
Efficiency is a key factor to consider in machine learning model development and deployment. This is especially true for commercial applications, where training time is linked to profits and environmental concerns, and latency directly impacts user experience. Various cost indicators have been proposed and adopted to measure model efficiency, and these are often assumed to be correlated, leading many developers to report only some of them.
In the new paper The Efficiency Misnomer, a Google Research team examines contemporary cost indicators, arguing that no single one can sufficiently capture overall model efficiency and that they can even contradict each other. The researchers say selective or incomplete reporting of cost indicators can lead to partial conclusions and a blurred or incomplete picture of the practical considerations of different models, and offer suggestions designed to improve the reporting of model efficiency metrics.

The team summarizes their study’s main contributions as:
- We call out the intrinsic difficulty of measuring model efficiency within the context of deep neural networks.
- We present the advantages and disadvantages of each cost indicator and discuss why they might be insufficient as a standalone metric.
- While obvious, we show examples of how model efficiency might be misrepresented by incomplete reporting of these cost indicators. We characterize this problem, coin the term “efficiency misnomer,” and show that it is more prevalent than imagined.
- We briefly review some of the existing work that reports comparisons of different models with respect to a cost indicator and discuss the current common practices for analyzing the efficiency of algorithms.
Incomplete reporting across the spectrum of cost indicators can misrepresent a model’s efficiency and result in unfair or partial conclusions in model comparisons, a phenomenon the researchers term the “efficiency misnomer.”
The team takes the three most commonly used cost indicators — FLOPs, number of parameters, and throughput/speed — and identifies their shortcomings as standalone efficiency metrics. FLOPs, representing the number of floating-point multiplication-and-addition operations, does not take into account information such as degree of parallelism or hardware-related details like the cost of memory access. The number of parameters or model size can also be misleading when used as a standalone cost indicator, as a model can have very few trainable parameters and still be very slow if parameters are shared among many computational steps. Finally, throughput/speed often ignores implementation details, hardware optimizations and infrastructure details, which can result in unfair model comparisons across different infrastructures or hardware.

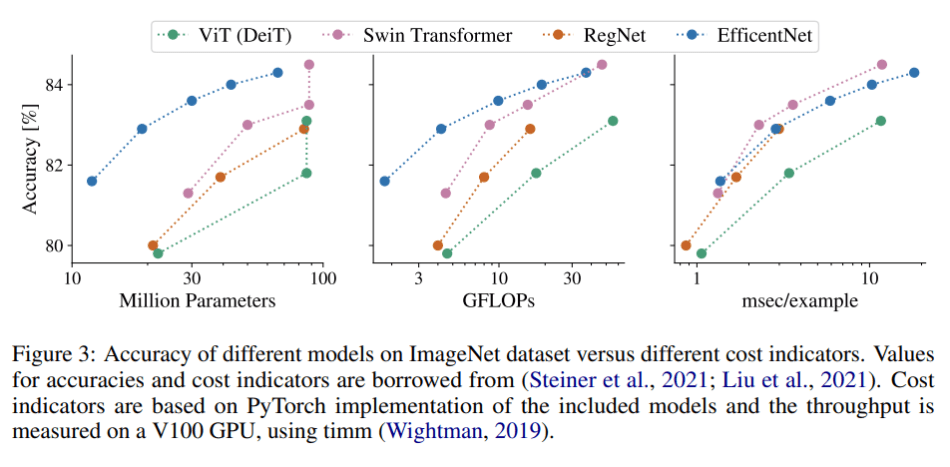
The team further explores how cost indicators may disagree with one another or lead to partial, incomplete and possibly biased conclusions; and provides many compelling examples. For example, comparing the D48 vision transformer (ViT) with 48-layers against the W3072 ViT with FFN dimension 3072 and QKV dimension 768 split across 8 heads in terms of FLOPs or number of parameter metrics would suggest that D48 is more efficient. In terms of speed, however, the W3072 ViT is not necessarily worse, as it has fewer sequential and more parallelizable operations.
Overall, the study demonstrates that highlighting results from a single cost indicator can be misleading, and that reporting and plotting curves using all available cost indicators will more fairly capture and represent overall model efficiency.
The paper The Efficiency Misnomer is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: Google Study Suggests Traditional Cost Indicator Reporting May Be a Misleading Measurement of Model Efficiency – Synced - AI Caosuo