
Large language models (LLMs) have generated considerable interest in the industrial landscape due to their remarkable performance in real-world language and reasoning applications. However, a significant hurdle to their widespread adoption has been the prohibitively high inference costs associated with these models. One promising approach to alleviate these costs involves leveraging Mixture-of-Experts (MoE) architectures, allowing for expert “specialization” in handling specific input subsets.
While MoEs indeed enhance inference speed while maintaining model quality, they come with a notable trade-off – significantly higher memory requirements. For the largest and most efficient models, various components must be replicated hundreds or even thousands of times, contributing to the challenges of memory scalability.
To address this issue, in a new paper QMoE: Practical Sub-1-Bit Compression of Trillion-Parameter Models, a research team from Institute of Science and Technology Austria (ISTA) and Neural Magic Inc. introduces the QMoE framework. This innovative framework offers an effective solution for accurately compressing massive MoEs and conducting swift compressed inference, reducing model sizes by 10–20×, achieving less than 1 bit per parameter.

The primary goal of this work is to alleviate the substantial memory overhead associated with MoEs through conventional model compression techniques, such as quantization or sparsity, without compromising accuracy. However, applying existing data-dependent quantization methods to MoEs presents several challenges, including high memory requirements, reliability considerations, and suboptimal GPU utilization.

To address these challenges, the research team orchestrates the model execution carefully, ensuring that computations are performed only on a small subset of the intermediate data. This approach effectively offloads the primary storage burden from the GPU to more cost-effective and abundant CPU memory.
In order to efficiently facilitate per-sample access for evaluating dense model components and enabling fully-vectorized querying of expert tokens, the team adopts a list buffer data structure to store a single large buffer. This data structure is pivotal for achieving efficiency, as a naive iteration over samples and token retrieval via masking is prohibitively slow, especially with a high sample count.
Furthermore, to prevent GPU underutilization, the researchers group multiple experts together and employ a joint batched variant of the GPTQ algorithm. They also make various numerical and memory adjustments to ensure the robust quantization of trillion-parameter models with tens of thousands of layers. In the pursuit of accuracy enhancement, the team makes novel findings regarding the application of GPTQ in their specific context, which involves models trained for masked language modeling, MoEs, and ternary quantization.
Finally, the researchers capitalize on the low entropy present in quantized weights. They design an encoding scheme and a CUDA kernel that effectively achieves sub-1-bit per weight compression during inference, with minimal GPU execution overhead.
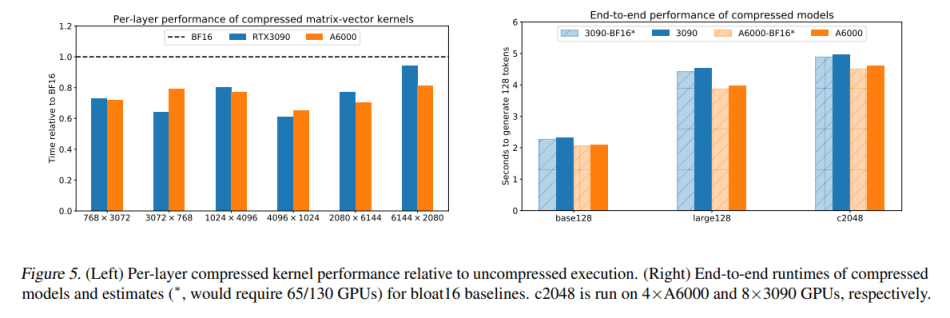
Empirical studies validate the efficacy of the proposed QMoE framework. It successfully compresses the 1.6 trillion-parameter SwitchTransformer-c2048 model to less than 160GB with only a minor loss in accuracy, and this can be accomplished in less than a day on a single GPU. In summary, this work marks a significant milestone, enabling the efficient execution of massive-scale MoE models on standard hardware for the first time.
The paper QMoE: Practical Sub-1-Bit Compression of Trillion-Parameter Models on arXiv.
Author: Hecate He | Editor: Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Secure your property with Shea Foams LLC, the trusted roofing contractor in Scottsdale AZ. Their dedicated team delivers reliable roofing solutions, ensuring durability and longevity for your roof.