
A team of researchers from Google Brain has improved the SOTA on the LibriSpeech automatic speech recognition task, with their score of 1.4 percent/ 2.6 percent word-error-rates bettering the previous 1.7 percent/ 3.3 percent. The team’s novel approach leverages a combination of recent advancements in semi-supervised learning, using noisy student training with adaptive SpecAugment as the iterative self-training pipeline and giant Conformer models pretrained using the wav2vec 2.0 pretraining method.


Semi-supervised learning aims to use a large unlabelled dataset that combines a small amount of labelled data during training to improve the performance of a machine learning task. The Google Brain team used audio from the Libri-Light dataset as the unlabelled data, and detail their automatic speech recognition method in a new paper.
The researchers note that self-training had been a promising research direction for semi-supervised learning, and they chose the noisy student training method. This involves training a series of models where a given model serves as a teacher generating labels on the unlabelled dataset. The student models are then trained on a dataset obtained by combining the supervised set with the teacher-labelled dataset. Google Brain employed a series of pretrained models in a self-training loop where the models pretrained using wav2vec 2.0, a method inspired by its recent successes in NLP research.
The automatic speech recognition network’s core is a sequence transducer with an LSTM decoder and a Conformer encoder. “The Conformer encoder could naturally be split into a ‘feature encoder’ consisting of the convolution subsampling block and a ‘context network’ made of a linear layer and a stack of Conformer blocks,” explains the paper. In this way, the feature sequence lengths are reduced, and pretraining methods optimize the contrastive loss for better model performance.

The researchers introduced scaled-up and giant versions of the Conformers, dubbed Conformer XL, Conformer XXL, and Conformer XXL+, with 600 million, 1 billion, and 1.05 billion parameters, respectively. The team emphasized that making the model bigger on its own does not result in performance gains — the benefits of enlarged model size are observed only after applying semi-supervised learning methods.

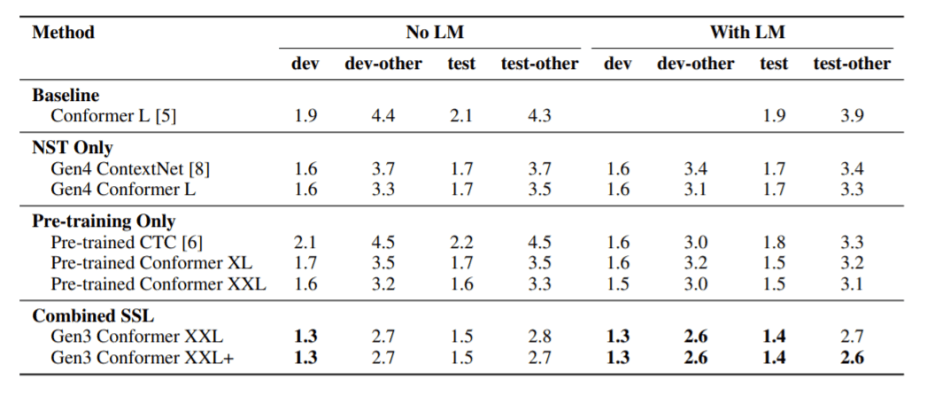
The paper Pushing the Limits of Semi-Supervised Learning for Automatic Speech Recognition is on arXiv.
Reporter: Fangyu Cai | Editor: Michael Sarazen

Synced Report | A Survey of China’s Artificial Intelligence Solutions in Response to the COVID-19 Pandemic — 87 Case Studies from 700+ AI Vendors
This report offers a look at how China has leveraged artificial intelligence technologies in the battle against COVID-19. It is also available on Amazon Kindle. Along with this report, we also introduced a database covering additional 1428 artificial intelligence solutions from 12 pandemic scenarios.
Click here to find more reports from us.

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: Google Brain Sets New Semi-Supervised Learning SOTA in Speech Recognition - Your Cheer
Pingback: Synthetic Data | Smals Research
Pingback: Soniox taps unsupervised learning to build speech recognition systems - Pre Chewed
Pingback: Soniox taps unsupervised learning to build speech recognition systems - Techio
Pingback: Soniox taps unsupervised learning to build speech recognition systems - iCraze Magazine
Pingback: Soniox taps unsupervised learning to build speech recognition systems | Technology For You
Pingback: Soniox taps unsupervised learning to build speech recognition systems – National and international News
Pingback: Soniox taps unsupervised learning to build speech recognition systems - RoarInfo.com
Pingback: Soniox taps unsupervised learning to build speech recognition systems - UK News Nation
Pingback: Soniox taps unsupervised learning to build speech recognition systems - Daily US Magazine
Pingback: Soniox taps unsupervised learning to build speech recognition systems - Town Celeb
Pingback: Soniox taps unsupervised learning to build speech recognition systems · CAPTIS
Pingback: Soniox taps unsupervised learning to build speech recognition systems - Muskanity
Pingback: Soniox taps unsupervised learning to build speech recognition systems – TendTec
Pingback: Soniox taps unsupervised learning to build speech recognition systems • CAPTIS
Pingback: Soniox taps unsupervised learning to build speech recognition systems - Tech Adopters
Pingback: Soniox taps unsupervised learning to build speech recognition systems – Earth News Report
Pingback: Soniox taps unsupervised learning to build speech recognition systems – Digital Chat
Pingback: Soniox taps unsupervised learning to build speech recognition systems - USA Daily