
The increasing popularity of transformer architectures in natural language processing (NLP) and other AI research areas is largely attributable to their superior expressive capability when handling long input sequences. A major drawback limiting transformer deployment is that the computational complexity of their self-attention mechanism is quadratic with respect to the size of the sequences. Because the size of a transformer’s attention window cannot be easily scaled, the compute cost quickly becomes prohibitively expensive when processing very long documents such as books or source code repositories.
In the new paper Block-Recurrent Transformers, a team from Google Research and the Swiss AI Lab IDSIA proposes Block-Recurrent Transformer, a novel long-sequence processing approach that has the same computation time and parameter count costs as a conventional transformer layer but achieves significant perplexity improvements. The researchers describe the method as “a cheap and cheerful way to improve language modelling perplexity on long sequences.”


The proposed Block-Recurrent Transformer applies a transformer layer in a recurrent fashion along a sequence. Unlike traditional transformer models that attend directly to all previous tokens, the Block-Recurrent Transformer constructs and maintains a fixed-size state to summarize the sequence that the model has seen thus far, enabling the recurrent cell to operate on a block of tokens that can be scaled up to a large size.
To improve efficiency, the method processes all tokens in parallel within a block. Processing the sequence in blocks can also be useful for propagating information and gradients over longer distances without causing catastrophic forgetting issues in the network.
Notably, because the recurrent cell also operates on a block of state vectors rather than a single vector, the size of the recurrent state is orders of magnitude larger than that of long short-term memory (LSTM) recurrent neural networks — a classical approach for handing long sequences — leading to significantly improved model capability for capturing the past.
The researchers explain their Block-Recurrent Transformer’s “strikingly simple” recurrent cell consists for the most part of an ordinary transformer layer applied in a recurrent fashion along the sequence length and uses cross-attention to attend to both the recurrent state and the input tokens. The method thus maintains a low cost burden in terms of computation time and parameter count. Also, because the recurrent cell uses existing transformer code, it is easy to implement.
The team evaluated their Block-Recurrent Transformer on three long documents: PG19, arXiv, and GitHub. They used the task of auto-regressive language modelling, where the goal is to predict the next token in a sequence.
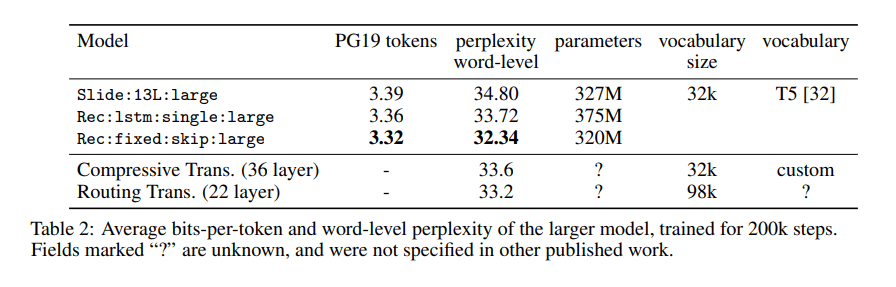
In the experiments, the Block-Recurrent Transformer demonstrated lower perplexity (lower is better) than a Transformer XL model with a window size of 2048 while achieving a more than 2x runtime speedup.
The researchers say their method was inspired by and mimics how humans process long text sequences. For example, rather than attempting to commit a novel to memory verbatim, readers construct a mental model summarizing the story thus far with respect to characters, relationships, plot points, etc. Humans also tend to process information in blocks (sentences or paragraphs), parsing then processing and interpreting the information using background knowledge from their mental model, and finally updating their mental model with the new information. Block-Recurrent Transformer similarly parses a text block by running it through a transformer stack and uses cross-attention so tokens in the text can attend to recurrent states (i.e. the mental model). The recurrent states are then updated by cross-attending to the text.
The team hopes future research and improvements can realize the full potential of their proposed recurrent architecture.
The paper Block-Recurrent Transformers is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
0 comments on “Google & IDSIA’s Block-Recurrent Transformer Dramatically Outperforms Transformers Over Very Long Sequences”