
What if a language model could acquire new knowledge by simply reading and memorizing new data at inference time? That’s the intriguing premise of Google’s ICLR 2022 conference paper Memorizing Transformers.
Conventional language models require training or fine-tuning to gain new knowledge, a learning process that is time-consuming and can entail extremely high resource consumption. The Google researchers envision language models that memorize facts by storing them as key/value pairs in long-term memory, such that the model’s attention mechanism can access and extract the stored information as required. The method is designed to bypass costly training and fine-tuning procedures and enable language models to immediately obtain new knowledge.

The team demonstrates that approximate k-nearest-neighbour (kNN) lookup — a method widely used in information retrieval — can serve as a simple and effective way to increase the size of a model’s attention context. Unlike conventional long sequence attention methods that perform averaging or summarization of tokens at long distances, kNN lookup retrieves exact values even from distant contexts. Further, instead of adopting backpropagate gradients into external memory, the proposed method reuses keys and values computed on earlier training steps. This approach enables large amounts of memory to be saved and the external memory to easily scale to long sequences of up to 262k tokens without introducing unreasonable step time burdens.

In the team’s proposed kNN-augmented transformer, input text is tokenized and the tokens embedded into a vector space. The embedding vectors go through a series of transformer layers, each of which performs dense self-attention, followed by a feed-forward network (FFN). Long documents are split into subsequences of 512 tokens, with each subsequence used as the input for one training step. Unlike traditional methods, the subsequences are not shuffled; long documents are instead fed into the transformer sequentially, as with the Transformer-XL (Dai et al., 2019).
The kNN-augmented attention layer uses standard dense self-attention on the local context and does an approximate k-nearest-neighbour search into the external memory, resulting in significant compute speed improvements.
The team evaluated their kNN-augmented Memory Transformer on several language modelling tasks that involve long-form text: English-language books (PG-19), long web articles (C4), technical math papers (arXiv Math), source code (GitHub), and formal theorems (Isabelle).
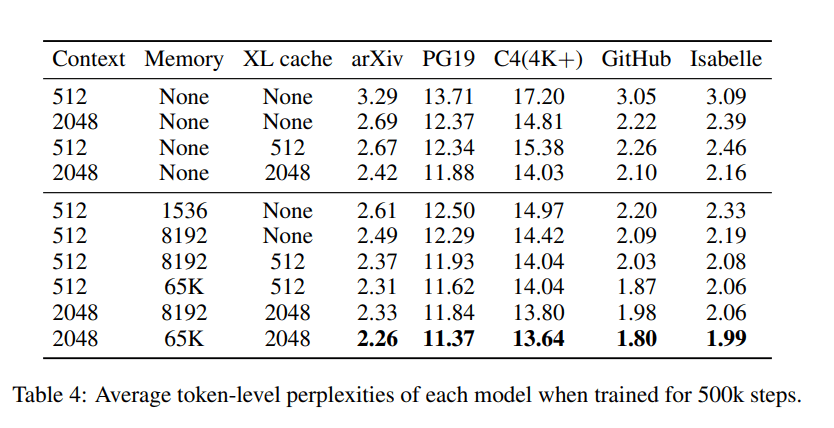
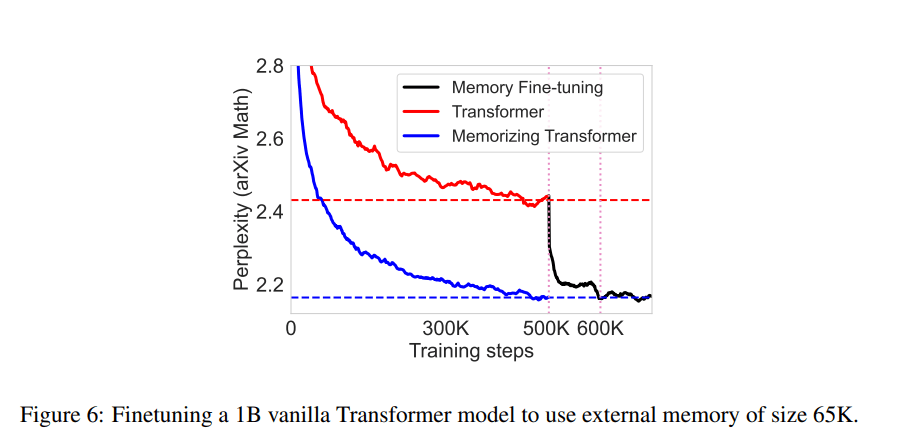
In the experiments, the proposed Memorizing Transformer recorded significant perplexity improvements over the baselines on all datasets and architectures, with performance comparable to a vanilla transformer with five times the parameter count. The team also observed that: 1) Model perplexity steadily improves with the size of external memory; 2) Models can generalize to larger memory sizes than they were trained on; and 3) The proposed models are actually using memory in the way that we had hoped, e.g. by looking up the definitions of lemmas in a theorem-proving corpus.
Overall, this work shows that the proposed kNN-augmented attention method can dramatically increase the context length a language model attends to, indicating its potential to leverage vast knowledge bases or code repositories.
The paper Memorizing Transformers is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
0 comments on “Google Extends Transformers for Immediate Knowledge Acquisition via a Simple New Data Read & Memorize Technique”