
Transformer architectures have established the state-of-the-art on natural language processing (NLP) and many computer vision tasks, and recent research has shown that All-MLP (multi-layer perceptron) architectures also have strong potential in these areas. However, although newly proposed MLP models such as gMLP (Liu et al., 2021a) can match transformers in language modelling perplexity, they still lag in downstream performance.
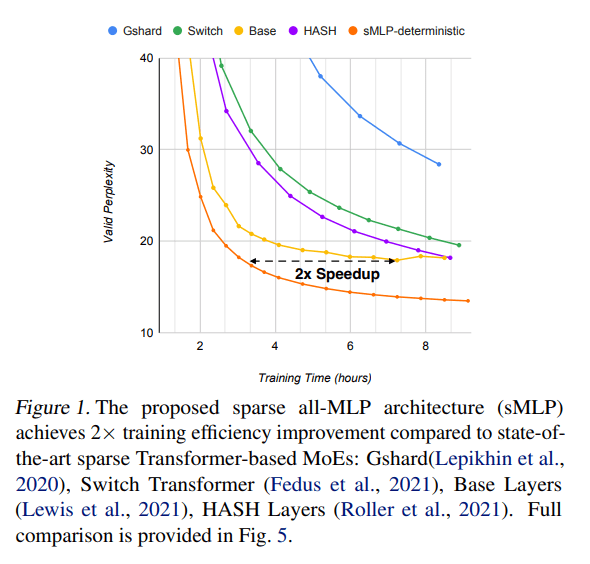
In the new paper Efficient Language Modeling with Sparse all-MLP, a research team from Meta AI and the State University of New York at Buffalo extends the gMLP model with sparsely activated conditional computation using mixture-of-experts (MoE) techniques. Their resulting sMLP sparsely-activated all-MLP architecture boosts the performance of all-MLPs in large-scale NLP pretraining, achieving training efficiency improvements of up to 2x compared to transformer-based mixture-of-experts (MoE) architectures, transformers, and gMLP.

The team believes their proposed sMLP is the first NLP work to combine all-MLP-based models with MoEs. The paper provides an in-depth analysis of why MLP architectures trail transformers in terms of expressiveness and identifies challenges in turning MLPs into sparsely activated MoEs, challenges sMLP addresses with a novel sMoE module and two routing strategies.

The sMLP architecture comprises both dense blocks and sparse blocks. Each sparse block contains a tMoE module (the team adopts MoE from base layers to replace the FFN module in dense transformers) and an sMoE module that replaces the self-attention module in transformers and the spatial gating unit in gMLP. The tMoE and sMoE blocks both contain expert modules that are used to process inputs and a gating function that decides which expert should process each part of the input.
The team also introduces two novel routing strategies: 1) Deterministic Routing, which sends hidden vectors to each expert by cutting the hidden dimension instead of learning the routing strategy; and 2) Partial Prediction, which, rather than predicting all the tokens in an input sentence, takes only the first 20 percent of tokens to learn a routing strategy that is then used to predict the remaining 80 percent.
These novel modules and routing strategies enable the proposed sMLP to significantly increase model capacity and expressiveness while keeping the compute relatively constant.


The team summarizes the setup and results of their empirical research as follows:
- We empirically evaluate sMLP performance on language modelling and compare with strong baselines of both sparse transformer-based MoEs such as Gshard (Lepikhin et al., 2020), Switch Transformer (Fedus et al., 2021), Base Layers (Lewis et al., 2021) and HASH Layers (Roller et al., 2021) as well as dense models including transformer (Vaswani et al., 2017b) and gMLP (Liu et al., 2021a). Our sMLP outperforms these models in terms of valid perplexities while obtaining up to 2x improvements in pretraining speed with the same compute budget. In addition, sMLP demonstrates good scalability where it still outperforms sparse transformer counterparts when scaled to 10B parameters with a large pretraining corpus of 100B tokens.
- Finally, we evaluate its zero-shot priming performance after pretraining on language modelling. Through head-to-head comparison, the proposed sparsely-activated all-MLP language model outperforms sparsely-activated transformers on six downstream tasks ranging from natural language commonsense reasoning to QA tasks. Compared with dense transformers such as GPT-3 (Brown et al., 2020b), our sMLP model achieves similar zero-shot performance despite being pretrained on a much smaller dataset (3x smaller than the dataset used by GPT-3) with less computing resources.
Overall, the study shows the proposed fully-sparse sMLP architecture outperforms state-of-the-art sparse transformer-based MoE models in terms of generalization, provides a 2x improvement in training efficiency on language modelling tasks, and achieves better accuracy in zero-shot in-context learning. In future work, the team hopes to explore all-MLP based MoE methods with encoder-only models with bidirectional attention.
The paper Efficient Language Modeling with Sparse all-MLP is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Interesting read—tech stuff like this can get pretty dense, so I needed a little mental break and ended up trying spin mama for some downtime. They had bonuses for new players, which made it easy to experiment without stressing over losses. I went through a few rounds, lost more than I expected at first, but then hit a surprisingly good win that made me feel like I’d actually accomplished something. It was a nice way to shift focus, and now I keep it bookmarked for whenever I need a quick escape from heavy research or long coding sessions.