
Machine learning researchers have in recent years turned their attention to neural language models to solve natural language understanding (NLU) tasks that require extensive world knowledge. To obtain sufficient factual knowledge, such advanced models require the retrieving and assimilating of factual information from multiple text sources.
In a new study, a research team from the University of Southern California and Google proposes TOME (Transformer Over Mention Encodings), a novel approach to factual knowledge extraction for NLU tasks. A transformer model with attention over a semi-parametric representation of the entire Wikipedia text corpus, TOME can extract information without supervision and achieves strong performance on multiple open-domain question answering benchmarks.

For NLU tasks that require extensive factual knowledge, studies have suggested representing information present in a text corpus through the construction of a virtual knowledge base (VKB). In the paper Mention Memory: Incorporating Textual Knowledge into Transformers Through Entity Mention Attention, the researchers advance this approach, incorporating a VKB into a language model by using it as external memory (“mention memory”), and performing attention over the entire VKB within a transformer model, enabling synthesizing and reasoning over multiple information sources in the corpus.
The benefits of the TOME approach can be summarized as:
- TOME retrieves entity mention representations corresponding to specific entity attributes or relations described in the corpus. This retrieval is much more fine-grained than aggregate entity retrieval methods, and the fine-grained retrieval also allows users to see more precisely what knowledge the model’s predictions are based on.
- TOME retrieves dense representations, which, unlike raw text, are easy to incorporate into a transformer model without reprocessing the input. TOME is thus able to retrieve, assimilate and reason over information from many different sources within a single transformer model.
- The retrieval is latent, without direct or distant supervision on the retrieved results.

The proposed method represents knowledge as a set of dense vector representations for all entity mentions appearing in the Wikipedia corpus via two components: a mention encoder and the TOME model itself. The mention encoder distills information from entity mentions into high-dimensional mention encodings and gathers the encodings into a mention memory. The TOME model then applies sparse attention over the mention memory to integrate the external information into the transformer model.
In their empirical study, the team compared TOME with several baselines, including generative language models (T5); and entity embedding retrieval (Entities as Experts, OPQL), extractive retrieve-and-read (REALM) and generative retrieve-and-read (RAG, Fusion-in-Decoder) methods. The evaluations were conducted on open-domain claim verification and entity-based question answering tasks.
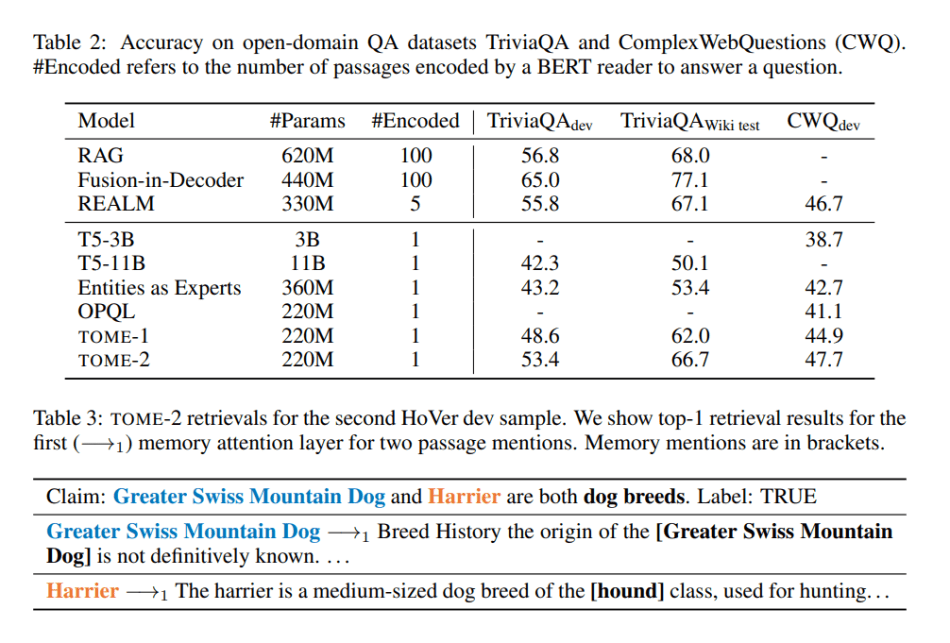
The results show that the proposed TOME achieves strong performance on open-domain knowledge-intensive tasks, learns to attend to informative mentions without any direct supervision, and can generalize to unseen entities using memory updates without retraining.
The paper Mention Memory: Incorporating Textual Knowledge into Transformers Through Entity Mention Attention is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: r/artificial - [R] Mention Memory: Incorporating Factual Knowledge From Various Sources Into Transformers Without Supervision - Cyber Bharat
I really like your blog it is very interesting and helpful for me
BEST NFT MINTING PLATFORM
I request you all to please visit us also- nft minting
mamlakaservices