
Photo-realistic free-view image synthesis of real-world scenes is an intriguing and important task in the computer vision field. Although the development of generative adversarial networks (GANs) has advanced such image synthesis to stunning new levels of quality, GANs cannot synthesize high-resolution 3D images and tend to be computationally expensive.
In the paper StyleNeRF: A Style-based 3D Aware Generator for High-resolution Image Synthesis (currently under double-blind review for ICLR 2022), researchers propose StyleNeRF, a 3D-aware generative model that can synthesize high-resolution images at interactive rates while preserving high-quality 3D consistency, and can even generalize to unseen views with control on styles and camera poses.

Most existing GAN models can only synthesize 2D images due to their lack of understanding of 3D images. To address this shortcoming, recent studies on generative models have incorporated neural radiance fields (NeRFs) to enable 3D image synthesis. However, due to the computationally expensive rendering process for NeRFs, such models struggle to synthesize high-resolution 3D images and are unsuitable for interactive applications.

To tackle these issues, the proposed StyleNeRF integrates NeRFs into a style-based generator. To reduce the computational burden, NeRFs are only used to produce a low-resolution feature map that is then progressively upsampled to high resolution. The researchers also introduce several strategies to improve 3D consistency: a desirable upsampler that achieves high consistency while mitigating artifacts in the outputs; a novel regularization term that forces the output to match the rendering result of the original NeRF; and fixing view direction condition and noise injection issues.
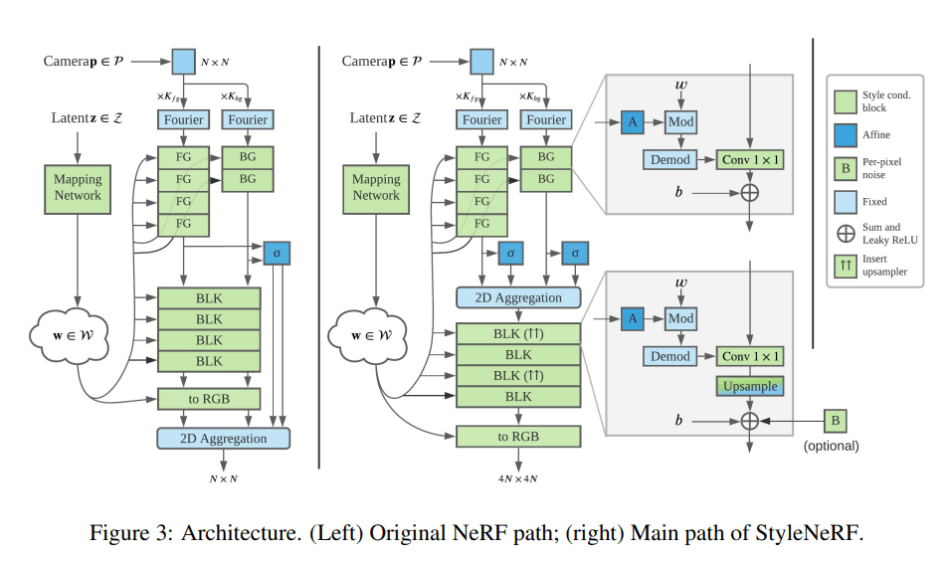
StyleNeRF comprises a mapping network and a synthesis network. Like StyleGAN2, its latent codes are sampled from standard Gaussian and processed by a mapping network. The output style vectors are broadcast to the generator blocks, a NeRF++ variant is employed as the backbone, and multi-level perceptrons (MLPs) are used to predict density and colour.
The team evaluated StyleNeRF on four high-resolution unstructured real datasets: FFHQ (Karras et al., 2019), MetFaces (Karras et al., 2020a), AFHQ (Choi et al., 2020) and CompCars (Yang et al., 2015). They chose a voxel-based method, HoloGAN, and three radiance field-based methods, GRAF, π-GAN and GIRAFFE, as their baselines.


In experiments, StyleNeRF consistently outperformed the baselines on all datasets, demonstrating significant gains in both Frechet Inception Distance (FID) and Kernal Inception Distance (KID) scores. The proposed method also enabled rendering at interactive rates and achieved significant speedups over voxel and pure NeRF-based methods, with performance comparable to GIRAFFE and StyleGAN2. The researchers note that StyleNeRF also enables explicit camera control, style mixing and interpolation, and style inversion and editing.
Overall, the study shows that StyleNeRF can efficiently synthesize photo-realistic high-resolution images with high multi-view consistency and explicit camera control at interactive rates, and outperforms previous 3D-aware generative methods.
The paper StyleNeRF: A Style-based 3D Aware Generator for High-resolution Image Synthesis is on OpenReview.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: r/artificial - [R] StyleNeRF: A 3D-Aware Generator for High-Resolution Image Synthesis with Explicit Style Control - Cyber Bharat