
While the power and performance of today’s large language models (LLMs) are beyond anything previously seen from AI, so too are their massive computational requirements. Spiking neural networks (SNNs) — which only transmit relevant information when a neuron’s threshold is met — have emerged as an energy-efficient alternative to traditional artificial neural networks. SNNs however have yet to match the performance of deep neural networks (DNN), and their effectiveness on language generation tasks remains unexplored.
In the new paper SpikeGPT: Generative Pre-trained Language Model with Spiking Neural Networks, a research team from the University of California and Kuaishou Technology presents SpikeGPT, the first generative spiking neural network (SNN) language model. The team’s 260M parameter version achieves DNN-level performance while maintaining the energy efficiency of spike-based computations.

The team summarizes their main contributions as follows:
- We provide the first demonstration of language generation using direct SNN training;
- We achieve performance comparable to that of ANNs, while preserving the energy efficiency of spike-based computations;
- We have successfully combined the powerful Transformer architecture with SNNs, without the need for additional simulation time steps, by utilizing linearization and recurrent Transformer blocks.
SpikeGPT is a generative language model with pure binary, event-driven spiking activation units. Inspired by the RWKV RNN language model, SpikeGPT integrates recurrence into a transformer block to make it compatible with SNNs, eliminates the quadratic computational complexity, and enables the representation of words as event-driven spikes.
Moreover, combining recurrent dynamics with linear attention makes it possible for the SpikeGPT network to process streaming data in a word-by-word manner, commencing computation before the given words form a sentence while retaining the long-range dependencies in complex syntactic structures.
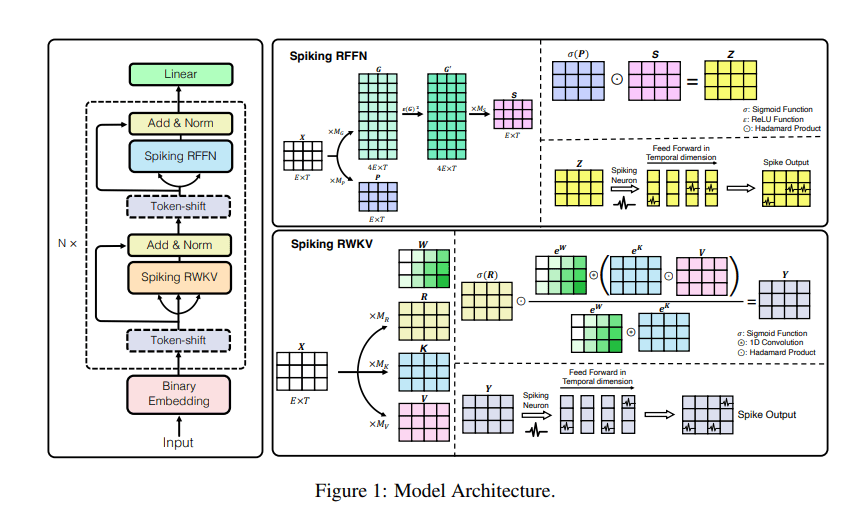
The team also introduces various techniques to boost SpikeGPT’s effectiveness: 1) A binary embedding step converts continuous outputs of the embedding layer into binary spikes to maintain consistency in the SNN binary activations, 2) A token shift operator combines information from the global context with the original token’s information to endow the token with better contextual information, and 3) A vanilla RWKV replaces the conventional self-attention mechanism to reduce computational complexity.

In their empirical study, the team trained SpikeGPT with three varying parameter scales (45M, 125M, and 260M parameters) and compared it with transformer baselines such as Reformer, Synthesizer, Linear Transformer and Performer on the Enwik8 dataset. In the evaluations, SpikeGPT achieved comparable results with 22x fewer synaptic operations (SynOps).
Overall, this work demonstrates how large SNNs can be trained to leverage advances in transformers via the proposed serialized version of their attention mechanisms and advances the possibility of significantly reducing LLMs’ compute burden by applying event-driven spiking activations to language generation. The researchers intend to continue testing and tweaking their model and will provide updates in their preprint paper.
The code implementation is available on the project’s GitHub. The paper SpikeGPT: Generative Pre-trained Language Model with Spiking Neural Networks is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Thanks for these tips.
Good explanation…………………………BY Salima FERHAT-FLL
Pingback: Kuaishou avslöjar KwaiYii och SpikeGPT, dess egenutvecklade stora språkmodeller - All Things Windows
Pingback: Kuaishou dezvăluie KwaiYii și SpikeGPT, modelele sale de limbaj mari dezvoltate de sine - All Things Windows
Pingback: Kuaishou presenta KwaiYii y SpikeGPT, sus modelos de lenguaje grande desarrollados por ellos mismos - All Things Windows
Pingback: Kuaishou svela KwaiYii e SpikeGPT, i suoi modelli di linguaggio di grandi dimensioni auto-sviluppati - All Things Windows
Pingback: Kuaishou ujawnia KwaiYii i SpikeGPT, własne duże modele językowe - All Things Windows
Pingback: Kuaishou onthult KwaiYii en SpikeGPT, zijn zelfontwikkelde grote taalmodellen - All Things Windows
Pingback: A Kuaishou bemutatja a KwaiYii és a SpikeGPT saját fejlesztésű nagy nyelvű modelljeit - All Things Windows
Pingback: Kuaishou Meluncurkan KwaiYii dan SpikeGPT, Model Bahasa Besar yang Dikembangkan Sendiri - All Things Windows
Pingback: Kuaishou stellt KwaiYii und SpikeGPT vor, seine selbst entwickelten großen Sprachmodelle - All Things IT
Pingback: Η Kuaishou αποκαλύπτει το KwaiYii και το SpikeGPT, τα αυτοαναπτυγμένα μοντέλα μεγάλων γλωσσών - All Things Windows
Pingback: Kuaishou Memperkenalkan KwaiYii dan SpikeGPT, Model Bahasa Besar yang Dibangunkan Sendiri - All Things Windows
Pingback: Inihayag ng Kuaishou ang KwaiYii at SpikeGPT, Ang Sariling Binuo Nito na Mga Malalaking Modelo ng Wika - All Things Windows
Pingback: Kuaishou revela KwaiYii e SpikeGPT, seus modelos de linguagem grandes autodesenvolvidos - All Things Windows
Pingback: Kuaishou เปิดตัว KwaiYii และ SpikeGPT โมเดลภาษาขนาดใหญ่ที่บริษัทพัฒนาขึ้นเอง - All Things Windows
Pingback: Kuaishou zbulon KwaiYii dhe SpikeGPT, modelet e saj të mëdha të gjuhëve të zhvilluara vetë - All Things Windows
Pingback: Kuaishou avduker KwaiYii og SpikeGPT, dets egenutviklede store språkmodeller - All Things Windows
Pingback: Kuaishou initiates trials of AI chatbots on Android platforms – Dao Insights – Play With Chat GTP