
The impressive performance of today’s neural language models (LMs) is attributed to their ability to memorize and leverage a large amount of factual knowledge from their massive training data. While a variety of third-party fact-checking services have emerged in recent years to identify misinformation and disinformation in social media posts, news coverage, etc., it remains challenging to directly track LMs’ learned knowledge back to specific training data for analysis and verification. Amid growing public concerns regarding a lack of transparency in AI systems, the “fact-tracing” of LM outputs back to the specific data that informed them remains a crucial but relatively underexplored task.
In the new paper Tracing Knowledge in Language Models Back to the Training Data, a research team from MIT CSAIL and Google Research presents a new benchmark for tracing language models’ assertions back to the associated training data, aiming to establish a principled ground truth and mitigate the high compute demands for large LM training.

The team first identifies the main obstacles hindering efficient fact tracing in LMs: 1) It is unclear how to obtain the ground truth data, i.e. what exactly does it mean for a training example to be “responsible” for a factual statement?; and 2) Traditional influence-based methods for linking predictions back to training data quickly become computationally prohibitive due to the billions of parameters in today’s LMs.
To address these issues, the team explores the feasibility of fact tracing in LMs by constructing an evaluation dataset with unambiguous ground-truth information with regard to the origins of specific facts; and implementing a tractable procedure that enables applying fact-tracing methods to large-scale LMs.

The researchers built their evaluation dataset by adopting a specialized training corpus — the TREx dataset (Elsahar et al., 2018) — which identifies all sentences that do or do not express a particular fact. Training with the TREx dataset thus enables the researchers to obtain the ground truth “proponents” responsible for a given LM prediction.
To mitigate the extremely high costs of influence computation, the team applied a simple reranking setup commonly used in information retrieval, where attribution is run not on every training example but rather only on a small subset of candidate examples that include the ground truth proponents and “distractor” examples that are not true proponents. Having the model identify the true proponents amid the challenging distractors enables the team to differentiate the performance of multiple fact-tracing methods.
In their empirical study, the team used their proposed benchmark to evaluate both gradient-based (Koh and Liang, 2017; Pruthi et al., 2020) and embedding-based (Rajani et al., 2020) influence methods on information retrieval tasks. They also included a basic information retrieval (IR) technique (BM25, Robertson et al., 1995; Lv and Zhai, 2011) that cannot access the LM and simply selects training examples that show high lexical overlap with the model’s prediction.

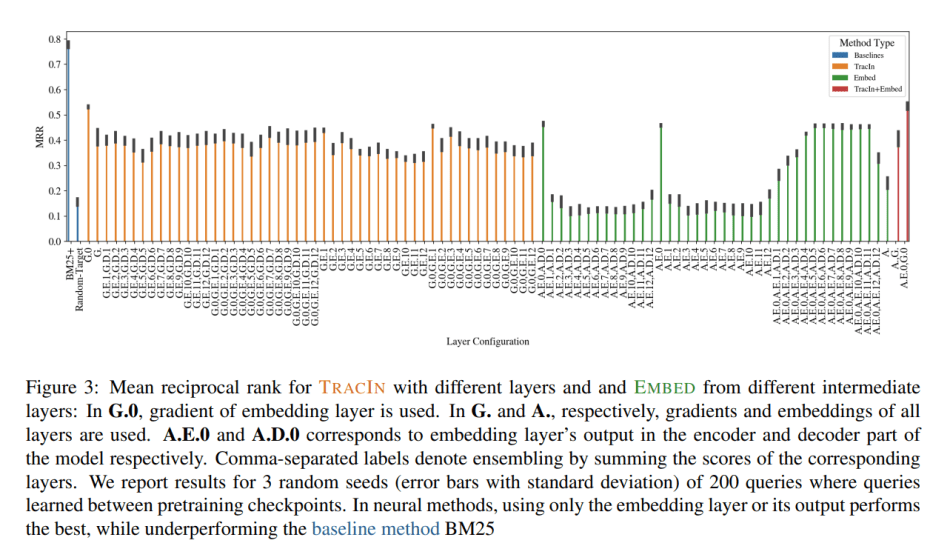
Somewhat surprisingly, the results show that the simple BM25 IR approach with no tuning outperforms both of the influence approaches. Even with extensive hyperparameter tuning and under evaluation setups designed to favour them, current influence-based methods could not reliably identify training examples known to be responsible for specific model predictions.
The team also investigated the effects of layer selection, model checkpoints and fine-tuning approaches, an analysis that pointed to gradient saturation as a key factor affecting the fact-tracing performance of current methods. The team concludes that significant work remains to be done before the theoretical benefits of influence techniques for fact tracing can translate into empirical success.
The team hopes their new benchmark will encourage future research on fact tracing by establishing a principled ground truth and mitigating high computational costs.
The paper Tracing Knowledge in Language Models Back to the Training Data is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
good article