
Large-scale language-based foundation models such as BERT, GPT-3 and CLIP have exhibited impressive capabilities ranging from zero-shot image classification to high-level planning. In most cases, these large language models, visual-language models and audio-language models remain domain-specific and rely highly on the distribution of their training data. The models thus obtain different although complementary common-sense knowledge within specific domains. But what if such models could effectively communicate with one another?
In the new paper Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language, Google researchers argue that the diversity of different foundation models is symbiotic and that it is possible to build a framework that uses structured Socratic dialogue between pre-existing foundation models to formulate new multimodal tasks as a guided exchange between the models without additional finetuning.

This work aims at building general language-based foundation models that embrace the diversity of pre-existing language-based foundation models by levering structured Socratic dialogue, and offers insights into the applicability of the proposed Socratic Models on challenging perceptual tasks.
The team summarizes their paper’s main contributions as: “
- The Socratic Models framework.
- Demonstration of an egocentric perception system using Socratic Models.
- Qualitative results on video understanding (synthesizing video snippets from a full day of activity) that is not covered by existing benchmark datasets.
- Qualitative comparisons to a state-of-the-art model (Mokady, Hertz, and Bermano 2021) on the task of single-image captioning in egocentric and Internet image domains.
- Quantitative comparisons to state-of-the-art video understanding models on the popular MSR-VTT (Xu et al. 2016; Yu, Kim, and Kim 2018) dataset for video-to-text retrieval.
- A framework for unsupervised quantitative model selection of Socratic Models through sub-model ablations.”


A Socratic Model (SM) comprises multiple pretrained language-interactable foundation models that are united under a zero-shot setting to perform new downstream tasks. The team builds sub-models with shared embedding spaces, and uses multi-model interactions to perform joint inference. These guided multi-model exchanges are then used to build a Socratic Model without finetuning. This cross-referencing design enables the SMs to share the common-sense knowledge that pre-existing foundation models have learned.

The paper presents several SM case studies, including egocentric perception, image captioning, and video-to-text retrieval. The examples show that SMs can offer insightful discoveries for complex tasks, such as generating freeform answers to contextual questions about egocentric video by summarizing the video into a short story and then answering the corresponding questions.
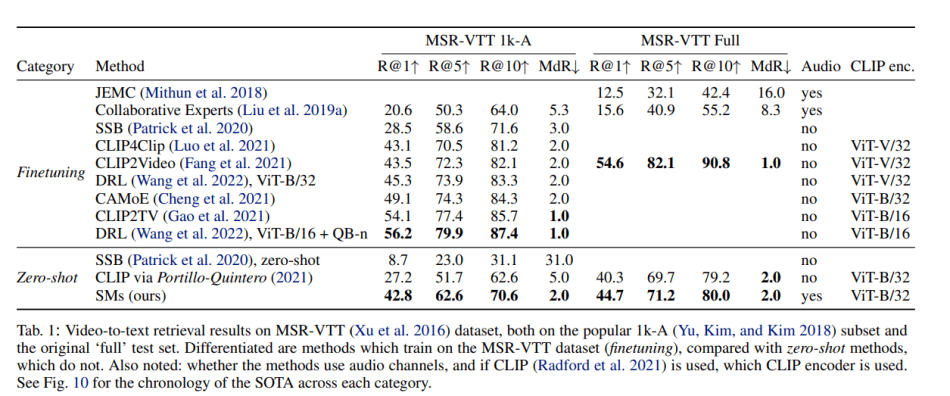
Notably, the study also shows that SMs can generate high-quality captions for Internet images and outperform state-of-the-art methods on zero-shot video-to-text retrieval, scoring an impressive 42.8 R@1 on the MSR-VTT 1k-A dataset.
The team believes their work demonstrates a strong domain transfer and robustness capability and hopes it can shed light on the potential for building simple yet general and effective AI systems that capture new multimodal representations under zero-shot settings without requiring training on additional domain-specific data or model finetuning.
The prototypes are available on the project’s GitHub Pages. The paper Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: Google Builds Language Models with Socratic Dialogue to Improve Zero-Shot Multimodal Reasoning Capabilities | Synced – Notes de Francis