
In his 2020 bestseller The Alignment Problem, author Brian Christian writes on the real-world dangers of powerful AI models: “The problem, of course, with a system that can, in theory, learn just about anything from a set of examples is that it finds itself, then, at the mercy of the examples from which it’s taught.”
While today’s large-scale pretrained language models like Open AI’s GPT-3 have achieved astounding performance across a wide range of natural language processing (NLP) tasks, such models can often generate unintended outputs that are not in accordance with users’ instructions. Moreover, these outputs can also be biased, untruthful or toxic, potentially resulting in negative societal impacts.
In the new paper Training Language Models To Follow Instructions With Human Feedback,an OpenAI research team leverages reinforcement learning from human feedback (RLHF) techniques (Christiano et al., 2017; Stiennon et al., 2020) to make significant progress on better aligning large language models with users’ intentions. In evaluations, the team’s proposed InstructGPT models are shown to be better at following instructions than GPT-3 while also generating outputs that are more truthful and less toxic.

InstructGPT is designed to encompass both explicit intentions (following user instructions) and implicit intentions (staying truthful, and not being biased, toxic, or otherwise harmful). The researchers borrow from the work of Askell et al. (2021) to characterize desirable language models as helpful (they should help the user solve their task), honest (they shouldn’t fabricate information or mislead the user), and harmless (they should not cause physical, psychological, or social harm to people or the environment).

The high-level InstructGPT process comprises three steps: 1) Collect demonstration data and train a supervised policy; 2) Collect comparison data and train a reward model; and 3) Optimize a policy against the reward model using PPO (Proximal Policy Optimization, Schulman et al., 2017).
The core technique in InstructGPT model training and fine-tuning is RLHF, which uses human preferences as a reward signal. The researchers use a dataset of human-written demonstrations submitted to their API to train supervised learning baselines, then compile a dataset of human-labelled comparisons between two model outputs on a larger set of prompts. They then train a reward model (RM) on this dataset to predict which output their labellers would prefer, and fine-tune the GPT-3 policy to maximize this reward using the PPO algorithm.
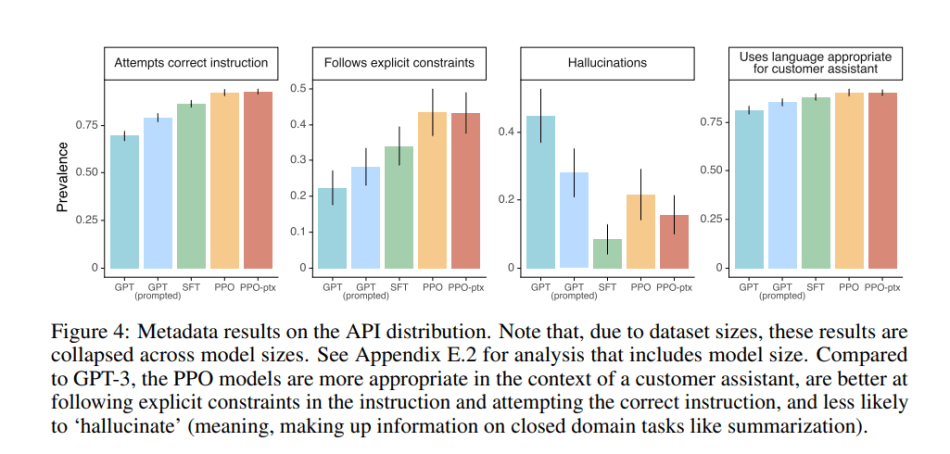


In their empirical study, the team evaluated InstructGPT on the API prompt distribution and public NLP datasets. They summarize their findings as:
- Labellers significantly prefer InstructGPT outputs over outputs from GPT-3.
- InstructGPT models show improvements in truthfulness over GPT-3.
- InstructGPT shows small improvements in toxicity over GPT-3, but not bias.
- We can minimize performance regressions on public NLP datasets by modifying our RLHF fine-tuning procedure.
- Our models generalize to the preferences of “held-out” labellers that did not produce any training data.
- Public NLP datasets are not reflective of how our language models are used.
- InstructGPT models show promising generalization to instructions outside of the RLHF fine-tuning distribution.
- InstructGPT still makes simple mistakes.
Overall, the results show that InstructGPT can significantly improve GPT behaviour on a wide range of tasks, demonstrating fine-tuning with human feedback as a promising direction for better aligning large language models with human intent. The researchers plan to continue developing their techniques to make such language models both safer and more helpful.
The paper Training Language Models To Follow Instructions With Human Feedback is on openai.com.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
But is it available for users to leverage when training their own applications through the GPT model?