
ChatGPT’s ability to generate coherent and comprehensive essays on any topic in seconds has made it both a game-changing information resource and the bane of educators. OpenAI’s conversational large language model amassed millions of daily users in the weeks following its release — but also found itself banned by school districts in the US, Australia, France and India.
While powerful large language models (LLMs) like ChatGPT (OpenAI, 2022), PaLM (Chowdhery et al., 2022), and GPT-3 (Brown et al., 2020) have countless beneficial applications, they can also be used to cheat on homework assignments or to write convincing-but-inaccurate news articles. Moreover, they often generate false information. The task of differentiating machine-generated from human-written text has thus become crucial in many domains. But as LLM outputs become increasingly fluent and humanlike, this task becomes increasingly difficult.
A Stanford University research team addresses this issue in the new paper DetectGPT: Zero-Shot Machine-Generated Text Detection Using Probability Curvature, presenting DetectGPT, a novel zero-shot machine-generated text detection approach that uses a probability curvature to predict whether a candidate passage was generated by a particular LLM.

The team summarizes their study’s main contributions as follows:
- The identification and empirical validation of the hypothesis that the curvature of a model’s log probability function tends to be significantly more negative at model samples than for human text.
- DetectGPT, a practical algorithm inspired by this hypothesis that approximates the trace of the log probability function’s Hessian to detect a model’s samples.

This work focuses on the task of zero-shot machine-generated text detection: given a sample text (“candidate passage”), the model learns to predict whether it was generated by a particular source LLM.
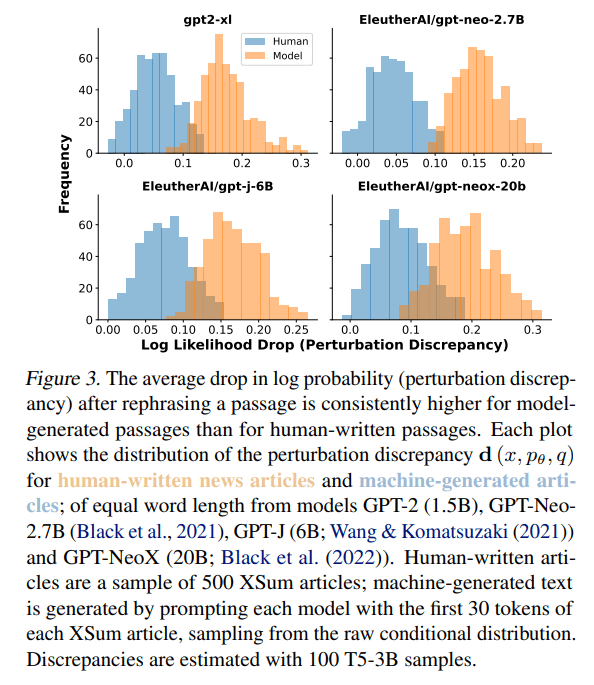
Working under a zero-shot setting, DetectGPT does not require human-written or generated samples for training; instead, it leverages generic pretrained mask-filling models to generate minor perturbations of the candidate passage. DetectGPT then operates on the assumption that samples from a particular source model normally lie in areas of negative curvature of the log probability function of that source model.


To evaluate DetectGPT’s effectiveness, the team compared it with existing zero-shot methods such as Rank, LogRank and Entropy. They used the XSum dataset (Narayan et al., 2018) for fake news detection and the Wikipedia paragraphs from SQuAD contexts (Rajpurkar et al., 2016) and Reddit WritingPrompts (Fan et al., 2018) datasets for detection in academic and creative writing. In the experiments, DetectGPT outperformed the strongest zero-shot baseline by over 0.1 AUROC (area under the receiver operating characteristic, a classification performance metric) on XSum and demonstrated a 0.05 AUROC improvement on SQuAD Wikipedia contexts. DetectGPT also achieved performance competitive with supervised detection models trained on millions of samples.
Just five days after this paper was published, OpenAI released its own AI Text Classifier detection tool. Reaction to these tools has been mixed, with a tweet from UC Berkeley student Charis Zhang summing up the skeptics’ position: “There was a time where GPT generated texts were easily detectable, largely not the case today. Also, ppl don’t copy & paste directly from GPT without changing it up, which throws any AI detection model off completely.”
The paper DetectGPT: Zero-Shot Machine-Generated Text Detection Using Probability Curvature is on arXiv.
Author: Hecate He | Editor: Michael Sarazen, Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
It’s exciting to see Stanford’s research on DetectGPT! Developing a method for detecting machine-generated text is essential, especially as language models become increasingly sophisticated and difficult to distinguish from human-generated text. It would be great if you could share more about tomb of the mask. Thanks again.
The arms race between AI text generation and AI text detection is ongoing. While DetectGPT represents a promising step forward, the challenge of reliably bitlife simulator identifying machine-generated text remains significant.
I recently discovered Snow Rider 3D and honestly it’s one of the most addictive casual games I’ve played. The thrill of sliding down snowy hills while dodging obstacles gives me such an adrenaline rush. Highly recommended if you need a fun way to relax after work.
DetectGPT sounds really cool! It’s getting harder and harder to tell what’s real online. Makes you wonder how accurate things like a Borderline Personality Disorder Test even are now, with all this AI text floating around. I hope this tech helps!
Curvature-based detection is an interesting angle, but I feel like we’re just going to be playing cat and mouse forever. Feels as unnecessary as having to look up what is a heic file just to open a photo.