
Studies on various machine learning models have shown that applying neural scaling laws — increasing compute, model size, and pretraining data — can reduce errors and significantly improve model performance. But this approach is far from ideal, as the benefits of scaling are relatively weak and unsustainable considering the huge additional computation costs.
In the NeurIPS 2022 Outstanding Paper Beyond Neural Scaling Laws: Beating Power Law Scaling via Data Pruning, a research team from Stanford University, University of Tübingen and Meta AI demonstrates in theory and practice how data pruning techniques can break beyond power law scaling of error versus dataset size.

The team summarizes their main contributions as follows:
- Employing statistical mechanics, we develop a new analytic theory of data pruning in the student-teacher setting for perceptron learning, where examples are pruned based on their teacher margin, with large (small) margins corresponding to easy (hard) examples.
- The theory quantitatively matches numerical experiments and reveals two striking predictions:
- The optimal pruning strategy changes depending on the amount of initial data; with abundant (scarce) initial data, one should retain only hard (easy) examples.
- Exponential scaling is possible with respect to pruned dataset size provided one chooses an increasing Pareto optimal pruning fraction as a function of initial dataset size.
- We show that the two striking predictions derived from theory hold also in practice in much more general settings.
- Motivated by the importance of finding good quality metrics for data pruning, we perform a large scale benchmarking study of 10 different data pruning metrics at scale on ImageNet, finding that most perform poorly, with the exception of the most compute intensive metrics.
- We leveraged self-supervised learning (SSL) to developed a new, cheap unsupervised data pruning metric that does not require labels, unlike prior metrics. We show this unsupervised metric performs comparably to the best supervised pruning metrics that require labels and much more compute.

The key idea informing this work is that power law scaling of error versus data suggests that some training data is redundant, and pruning such data could significantly reduce data size and the associated compute burden without degrading model performance.
To this end, the team establishes an analytic theory of data pruning in a perceptron’s teacher-student setting that predicts the generalization error of the student by calculating the deviation of the student-probe perceptron from the teacher. Because the generalization error depends on the metric (easy/hard), and the metric measures the (pruned) number of retained samples per dimension, it is possible to minimize it through optimal pruning and less “abundant” data.
Moreover, the team shows that Pareto optimal data pruning, where no further improvements are attainable through changes in the data, can beat power law scaling and further predict the information gain per sample added per dimension.
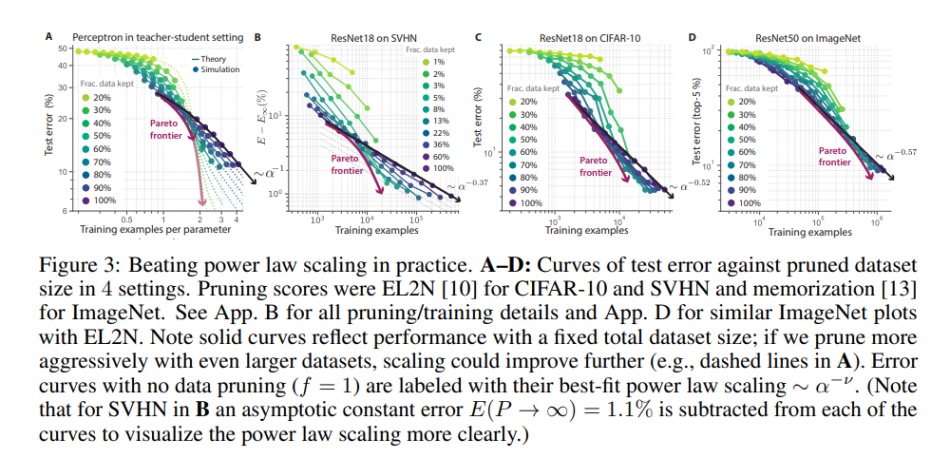

In their empirical studies, the team tested their theory on ResNets trained on SVHN, CIFAR-10, and ImageNet. The results show that applying the simple self-supervised pruning metric makes it possible to discard 20 percent of ImageNet data without sacrificing model performance.
Overall, this paper demonstrates the potential of the proposed data pruning approach for moving beyond slow power law scaling of error versus dataset size to faster exponential scaling, opening a new research avenue for reducing the high costs of modern deep learning.
The paper Beyond Neural Scaling Laws: Beating Power Law Scaling via Data Pruning is on OpenReview.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
0 comments on “NeurIPS 2022 | Meta AI, Stanford & Tübingen U Beat Neural Scaling Laws via Data Pruning”