
Most deep neural network training relies heavily on gradient descent, but choosing the optimal step size for an optimizer is challenging as it involves tedious and error-prone manual work.
In the NeurIPS 2022 Outstanding Paper Gradient Descent: The Ultimate Optimizer, MIT CSAIL and Meta researchers present a novel technique that enables gradient descent optimizers such as SGD and Adam to tune their hyperparameters automatically. The method requires no manual differentiation and can be stacked recursively to many levels.

The team addresses the limitations of previous gradient descent optimizers by enabling automatic differentiation (AD), which provides three main benefits:
- AD automatically computes correct derivatives without any additional human effort.
- It naturally generalizes to other hyperparameters (e.g. momentum coefficient) for free.
- AD can be applied to optimize not only the hyperparameters, but also the hyper-hyperparameters, and the hyper-hyper-hyperparameters, and so on.
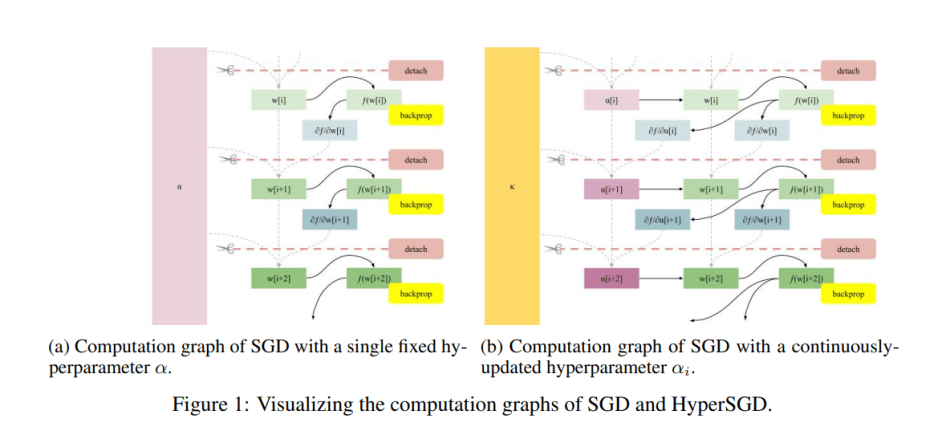
To enable the automatic computing of hypergradients, the team first “detaches” the weights from the computation graph before the next iteration of the gradient descent algorithm, which converts the weights to graph leaves by removing any inbound edges. This approach prevents the computation graph from growing with each step — which would result in quadratic time and intractable training.

The team also enables the backpropagation process to deposit gradients with respect to both weights and step size by not detaching step size from the graph, but detaching its parents instead. This leads to a fully-automated hyperoptimization algorithm.
To enable computing gradients automatically via AD, the researchers recursively feed HyperSGD itself as the optimizer to obtain a next-level hyperoptimizer, HyperSGD. AD can be applied in this manner to hyperparameters, hyper-hyperparameters, hyper-hyper-hyperparameters, and so on. As these optimizer towers grow taller, they become less sensitive to the initial choice of hyperparameters.

In their empirical study, the team applied their hyperoptimized SGD to popular optimizers such as Adam, AdaGrad and RMSProp. The results show that the use of hyperoptimized SGD boosts baseline performance by significant margins.
This work introduces an efficient technique that enables gradient descent optimizers to automatically tune their own hyperparameters and can be stacked recursively to many levels. A PyTorch implementation of the paper’s AD algorithm is available on the project’s GitHub.
The paper Gradient Descent: The Ultimate Optimizer is on OpenReview.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Very helpful article, thanks for this info.