
Automated information retrieval has become a leading paradigm for information access in today’s world, employed every time someone enters a query into a web search engine. Although the information retrieval field has seen rapid progress in recent years thanks to the development of deep neural networks that can retrieve knowledge from large-scale corpora containing millions to billions of passages, these models tend to have poor generalization capabilities and their performance can suffer from a lack of dedicated training data.
In the new paper Promptagator: Few-shot Dense Retrieval From 8 Examples, a Google Research team proposes Prompt-based Query Generation for Retriever (Promptagator), a novel and simple approach for few-shot retrieval that alleviates the data scarcity problem by leveraging large language model (LLM) prompting to generate synthetic task-specific training data.

The team summarizes their main contributions as follows:
- We analyze the previously overlooked differences across retrieval tasks in their search intents and query distributions and propose a Few-Shot Retrieval setting for the BEIR dataset. Our prompt and few-shot examples will be released to facilitate future research.
- We propose Promptagator, a simple recipe for few-shot retrieval by prompting with an LLM to generate synthetic task-specific training data. For the first time, end-to-end retrievers solely based on a few supervised examples can be strong and efficient to serve with Promptagator.
- Our experimental results show that, surprisingly, Promptagator with two-to-eight examples produced significantly better retrievers compared to recent models trained on MS MARCO or NQ that have over 500K human-annotated examples. Promptagator outperforms ColBERT v2 and SPLADE v2 on 11 retrieval tasks we tested, while reranking boosts results by another 5 points on the standard retrieval evaluation metric.

The proposed Promptagator aims to significantly increase the number of training examples by using available examples to prompt an LLM as a few-shot query generator and using the generated data to create task-specific retrievers. Promptagator comprises three main components: prompt-based query generation, consistency filtering, and retriever training.
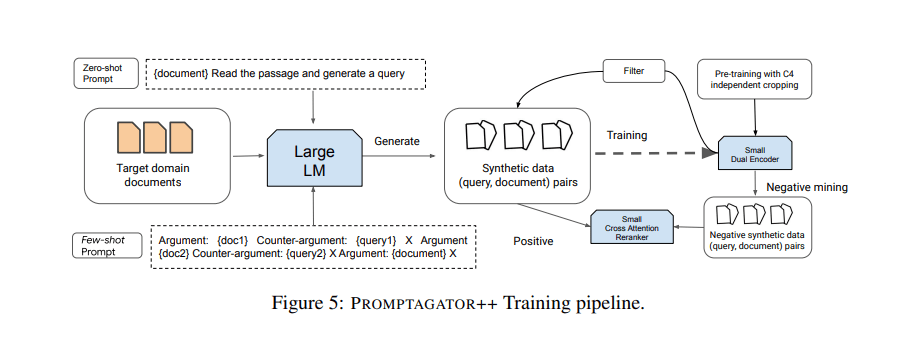
In the prompt-based query generation phase, a task-specific prompt and an LLM are jointly employed to generate queries for the target task via a target retrieval corpus. The consistency filtering step then cleans the generated data based on round-trip consistency. Finally, a retriever (a dual encoder in this work) and a cross attention reranker are trained using the generated data.
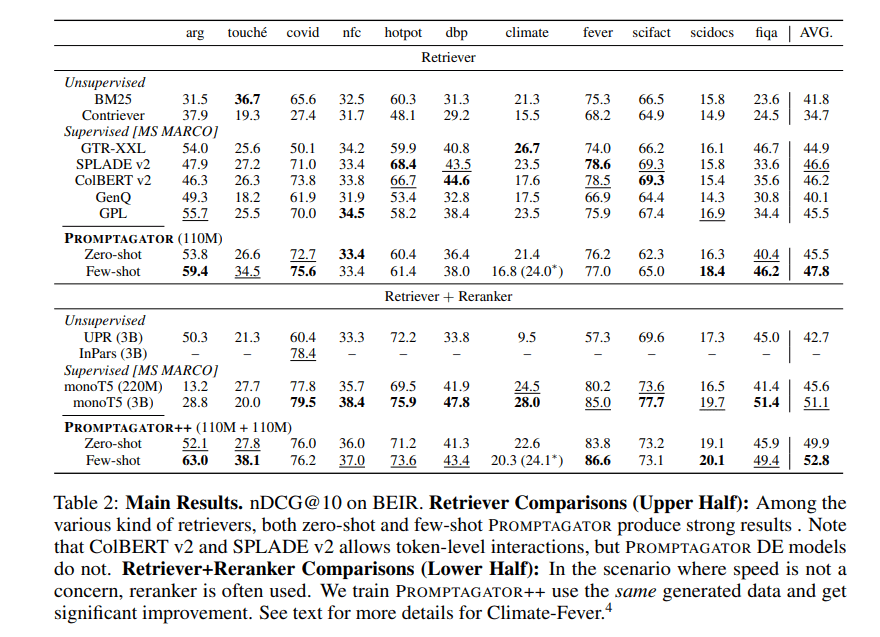
In their empirical study, the team compared Promptagator against baseline models such as ColBERT v2 and SPLADE v2, which are trained on the MS MARCO or Natural Questions (NQ) datasets with over 500K human-annotated examples. The results show that Promptagator can outperform both ColBERT v2 and SPLADE v2 while requiring no more than eight examples.
Overall, this work demonstrates the possibility of creating effective task-specific end-to-end retrievers using LLMs and few-shot examples rather than relying on massive human-annotated training data.
The paper Promptagator: Few-shot Dense Retrieval From 8 Examples is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
0 comments on “Google’s Promptagator Creates Task-Specific Neural Retrievers From Only 8 Examples”