
When it comes to large AI models, remarkable performance in a wide range of applications often brings a big budget for hardware and running costs. As a result, most AI users, like researchers from startups or universities, can do nothing but get overwhelmed by striking news about the cost of training large models.

Fortunately, because of the help from the open source community, serving large AI models became easy, affordable and accessible to most.
Now you can see how incredibly the 175-billion-parameter OPT performs in text generation tasks, and do it all online for free, without any registration whatsoever!
Time to get your hands dirty:
https://service.colossalai.org/
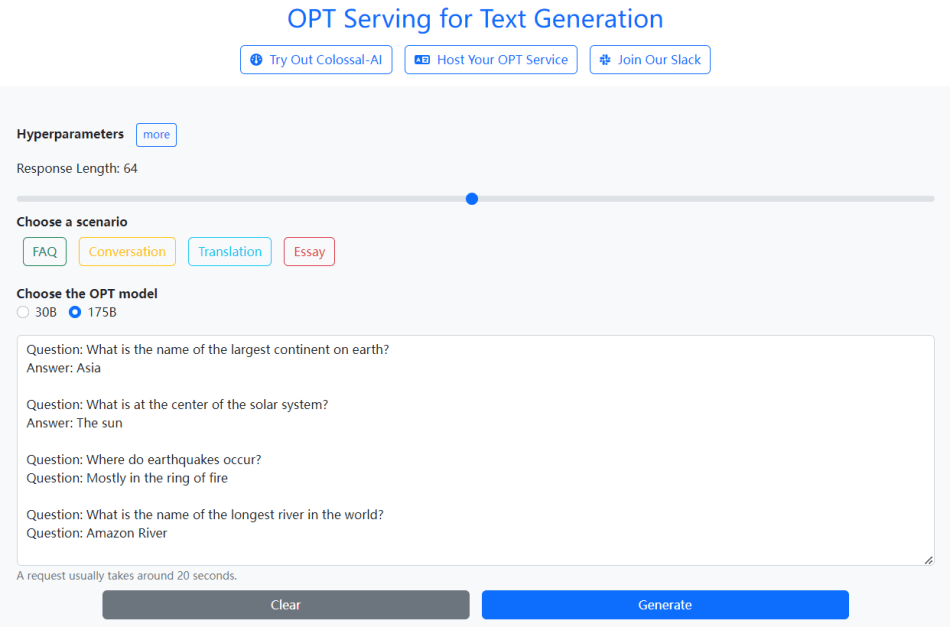
Quick Test
This service offers a variety of text generation tasks, including FAQ, Chatbot, Translation, Essay, etc.
You are asked to choose a scenario, such as FAQ, then enter the content, and click the blue Generate button. Now, wait for a few seconds and boom, you have your results.
Behind the Scenes
OPT-175B
To understand the technical principles of the big model inference we just experienced, first, let’s review the big model we just used.
The full name of OPT is Open Pretrained Transformer, which is a large-scale Transformer model (175 billion parameters) that has a similar performance to that of GPT-3.

Compared with GPT-3, which OpenAI has not yet disclosed the model weights of, Meta AI generously open-sources all the code as well as the model weights. It greatly promotes the applications of big AI models, and every developer can use them as the basis for developing personalized downstream tasks.
However, cutting-edge AI big models such as GPT-3, OPT-175B and AlphaFold far exceed the capacity of existing hardware, and complex and professional distributed technologies must be used for training and deploying inference services. Most of the existing systems also have problems such as high barriers to learning, low running efficiency, poor generality, difficult deployment, and lack of maintenance.
Facing this pain point, Colossal-AI, a unified deep learning system for the big model era, can efficiently and rapidly deploy large AI model training and inference with just a few lines of code, and promote the low-cost application and implementation of big models.
Rapidly Deploy Big AI Model Cloud Services with Open Source Colossal-AI
OPT Cloud Services
The rapid online deployment of the OPT-175B large model relies on the Colossal-AI big models ecosystem. With only a few lines of code, the parallel deployment of large models in the cloud can be completed.
From “unable” to “enable”:
The first problem of running large models is that a single unit of GPU memory cannot accommodate the huge amount of model parameters, and the inference requires not only throughput but also latency. So, it is an intuitive idea to use parallelism to solve this problem, and Colossal-AI can easily run a single model parallelly. The Colossal-AI ecosystem can better provide many application examples, including GPT, OPT, BERT, PaLM, AlphaFold, etc.
After obtaining the parallel OPT model, the next step is to deal with parameter loading, and Colossal-AI ecology also provides a decent solution. Users only need to refer to the sample code to simply provide the parameter name mapping relationship to complete the loading, finally put the model into the inference engine and set the corresponding hyperparameters. By now, the parallel inference of OPT backbone network is ready for service and meaningful natural language results can be created.
From “enable” to “enhance”:
After successfully running the parallel backbone network by overcoming obstacles such as memory wall and parallel parameter loading, Colossal-AI further improves inference performance by providing several optimizations for generation tasks that can achieve tens of times higher inference throughput.
Since OPT is oriented to generation tasks requiring an iterative process, the backbone model needs to be called multiple times for a single request. This makes the common batching strategy in inference not applicable, and the single-batch is inefficient. In addition, there are a lot of repeated calculations in the generation stage.
In order to release the potential parallelism of advanced hardware for generation tasks, Colossal-AI team added the left padding technique to make batching possible, the past cache technique to eliminate repeated computations in the generation stage, and introduced bucket batching technique to reduce meaningless computing.
Let’s first explain why generation tasks cannot directly use the common batching method. As shown in the figure below, since the length of input sequences usually varies, and most languages are written from left to right, it is difficult to generate meaningful results for shorter sentences or complex processing is required to be applied for the result, if we use the right padding. However, when we use left padding to fill the sentences, the generation side (right side) of each sentence is aligned, and new words can be generated simultaneously.

Right padding is not suitable for generative tasks

Left padding
Moreover, in the generation task, a single inference of the model can only generate a new word and the new word will be added to the end of the original sequence, then the newly-assembled sequence will be put into the model again to generate the next new word. Thus, there are many repeated computations in the iterative process. Especially for the Linear layer, which accounts for most of the computation, a lot of repeated computations are performed. Therefore, Colossal-AI developers added the past cache technique inside the model, which will temporarily store the output results of the Linear layer in the same generation task, and only one new word will flow into the Linear layer each time, greatly reducing the practical calculations required.

Generative task computation process. Past cache technique keeps the results of Linear layer computation of the same task. A new iteration only needs to compute one new word, then the new word will be added into cache for subsequent computations.
In addition, the Colossal-AI developers noticed that, unlike other tasks, the computation of different requests in generation tasks varies not only in input sentence lengths, but also in target output sentence lengths, and both lengths vary in a large range.
Therefore, Colossal-AI developers added the bucket batching technique, i.e., bucket sorting by input sentence length and target output sentence length, and the sequences in the same bucket are used as a batching, which greatly reduces the redundant computation, thereby significantly reducing the number of redundant computations.

Bucket batching puts tasks with similar input and output lengths in the same batch.
Colossal-AI for the big model era
Colossal-AI not only provides many excellent solutions for big models, but more importantly, it is completely open source!
Every developer can train their own big models based on Colossal-AI at low costs and deploy it as a cloud service. For example, on a 10GB RTX 3080, a model with 12 billion parameters can be trained, increasing the model capacity by 120 times compared with the original PyTorch.

Since being open source, Colossal-AI has reached No.1 in trending projects on GitHub and Papers With Code several times, together with other projects that have as many as 10K stars. Colossal-AI is already showing tremendous potential across a variety of fields, including medicine, autonomous vehicles, cloud computing, retail, and chip production. Further, now with the help of the open-source Colossal-AI, we are able to achieve an effective cloud service deployment swiftly.

Recently, Colossal-AI Team has been accepted and invited to deliver keynote speeches at a series of notable international conferences, including SuperComputing 2022 (SC22), Open Data Science Conference (ODSC), World Artificial Intelligence Conference (WAIC), and AWS Summit. In the event, Colossal-AI Team is going to share many up-to-date and amazing things and technologies of High Performance Computing (HPC) and Artificial Intelligence (AI) that will change the world. Follow us and stay tuned!
Open Source Code:https://github.com/hpcaitech/ColossalAI
Cloud Service Entry:https://service.colossalai.org/
Reference
https://arxiv.org/abs/2205.01068
https://sc22.supercomputing.org/

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
0 comments on “Using State-Of-The-Art AI Models for Free: Try OPT-175B on Your Cellphone and Laptop”