
Masked autoencoders (MAEs) are a self-supervised pretraining strategy for vision transformers (ViTs) that masks-out patches in an input image and then predicts the missing regions. Although the approach is both simple and effective, the MAE pretraining objective is currently restricted to a single modality — RGB images — limiting application and performance in real-life scenarios which typically present multi-modal information.
In the new paper MultiMAE: Multi-modal Multi-task Masked Autoencoders, a team from the Swiss Federal Institute of Technology Lausanne (EPFL) proposes Multi-modal Multi-task Masked Autoencoders (MultiMAE), a pretraining strategy that enables masked autoencoding to deal with multiple modalities and tasks. MultiMAE is trained using pseudo labelling, making the framework applicable to any RGB dataset.

MultiMAE’s design is based on conventional Masked Autoencoding but differs in two key aspects: 1) Along with RGB images, it can optionally also accept additional information modalities in the input (hence “multi-modal”), and 2) Its training objective accordingly includes predicting multiple outputs besides RGB images (hence “multi-task”).
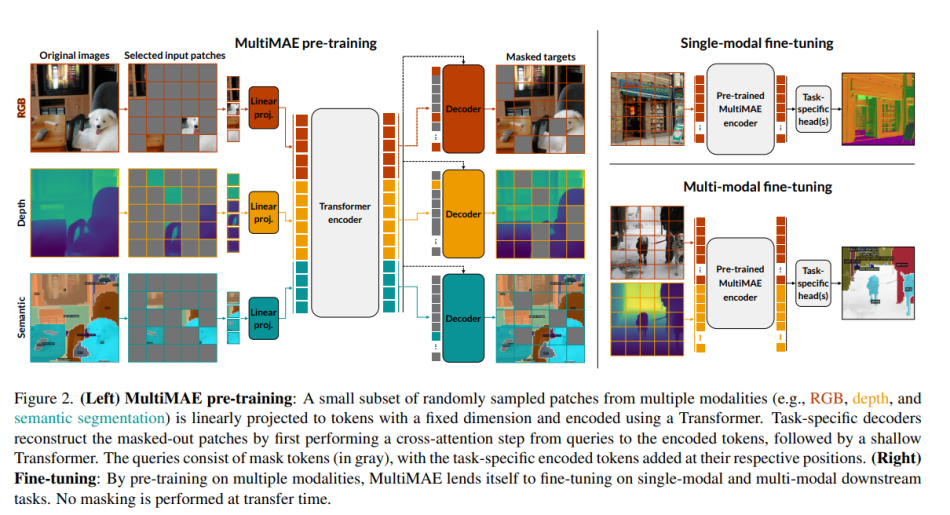
Architecturally, MultiMAE’s encoder is a ViT but with patch projection layers for each additional input modality and an additional global token with a learned embedding, similar to ViT’s class token. MultiMAE’s pretrained weights can thus be directly used in a standard single-modal ViT by loading only the desired input projections and ignoring all others.

To perform semantic segmentation patch projection, the researchers replace each class index with learned 64-dimensional class embeddings. Only a random subset of visible tokens is encoded, which achieves significant speedups and memory reduction and enables MultiMAE multi-modal pretraining with three dense input modalities. A separate decoder is used for each task, so the decoders’ compute scales linearly with the number of tasks and adds only minimal cost.
In their empirical study, the team pretrained MultiMAE on three tasks — image classification, semantic segmentation, and depth estimation — that they pseudo labelled on ImageNet-1K and then performed on the ImageNet, ADE20K, Taskonomy, Hypersim, and NYUv2 datasets.

The results demonstrate that MultiMAE retains the benefits of regular MAE when RGB is the only fine-tuning modality and that it can also leverage additional modalities such as depth and use pseudo-labelled depth or semantic segmentation to boost performance beyond the RGB-only setting. Further, the MultiMAE pretraining strategy produces notable gains in transfer performance.
The code, pretrained models and interactive visualizations are available on the project’s GitHub. The paper MultiMAE: Multi-modal Multi-task Masked Autoencoders is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
why are you lying , the model shows EXTREME REDICULUS overfitting LOL
the only believable image is the red bird.