
Studies have shown that increasing either input length or model size can improve transformer-based neural model performance. In a new paper, a Google Research team explores the effects of scaling both input length and model size at the same time. The team’s proposed LongT5 transformer architecture uses a novel scalable Transient Global attention mechanism and achieves state-of-the-art results on summarization tasks that require handling long sequence inputs.

The team summarizes their study’s contributions as:
- A new Transformer architecture, LongT5, that allows for scaling both input length and model scale at the same time.
- A new attention mechanism (TGlobal), which mimics ETC’s local/global mechanism but is a drop-in replacement to regular attention and can be used within existing Transformer architectures like T5.
- An analysis of model performance when varying both input length and model size of vanilla T5 and LongT5 models (pushing both models up to the maximum lengths they can handle before encountering memory issues), to understand the trade-offs in both performance and computation cost.
- State-of-the-art results on the arXiv, PubMed, BigPatent, and MediaSum datasets.

To explore the effects of scaling transformer architecture input length and model size at the same time, the team integrates long-input transformer attention and a PEGASUS-style Principle Sentences Generation pretraining objective (Zhang et al., 2019) into the scalable T5 model introduced by Raffel et al. in 2019.
The researchers’ proposed Transient Global (TGlobal) attention mechanism mimics the recently introduced ETC (Extended Transformer Construction) local/global mechanism (Ainslie et al., 2020), which uses local sparsity to reduce the quadratic cost when scaling to long inputs. ETC’s need for additional side inputs is removed to enable it to fit within the T5 architecture. As such, the TGlobal mechanism synthesizes global tokens on the fly at each attention layer, resulting in only a small performance degradation with respect to full attention at the same input length while enabling the model to scale to much larger input lengths and gain significant performance improvements.
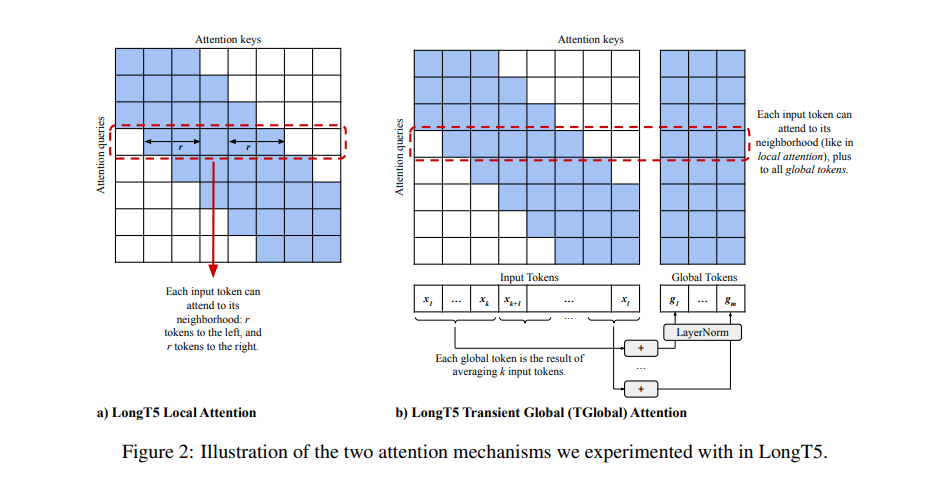
The team extends the original T5 encoder with global local attention sparsity patterns to effectively handle long sequences. Unlike T5, the LongT5 architecture employs two different attention mechanisms: local attention and TGlobal. For local attention, the researchers simply replace the T5 encoder self-attention operation with a sparse sliding window local attention operation following the implementation in ETC. For TGlobal, they modify ETC’s global-local attention in a “fixed blocks” pattern to allow input tokens to interact with each other in each layer of the encoder at a longer range than local attention’s local radius. Both of these attention mechanisms preserve desirable T5 properties such as relative position representations, support for example packing, and compatibility with T5 checkpoints.

The team evaluated LongT5 on summarization tasks using the CNN/Daily Mail, PubMed, arXiv, BigPatent, MediaSum, and Multi-News datasets, where it achieved state-of-the-art results on four of the six (PubMed, arXiv, BigPatent, and MediaSum) benchmarks. In question-answering tasks on the TriviaQA and Natural Questions datasets, the results show that increasing input length results in significant benefits. The researchers note however that they used a slightly different formulation than the original tasks, and so their results are not directly comparable to other existing approaches.
The team identifies future research directions that could further improve model efficiency, such as studying efficient attention mechanisms in the decoder and decoder-to-encoder attention pieces of the model, and incorporating additional long-input transformer ideas into the LongT5 architecture.
The paper LongT5: Efficient Text-To-Text Transformer for Long Sequences is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: r/artificial - [R] Google’s Transformer-Based LongT5 Achieves Performance Gains by Scaling Both Input Length and Model Size - Cyber Bharat
choosing a reliable essay writing agency is crucial. To find the most suitable writing expert, students need to consider the professionalism and reliability of the writing agency http://www.pnstudy.com/ , as well as its legality and compliance. Additionally, attention should be given to the service experience and after-sales guarantees. By comprehensively considering these factors, students can undoubtedly find the most suitable essay writing service provider and successfully complete various academic tasks.