
Can too much information hinder an AI model? Take a vehicle’s lane-keeping feature, whose input is a high-resolution camera delivering millions of bits of real-time information. The model needs but a fraction of this data related to vehicle orientation to function robustly. The consideration of additional data increases the compute burden, the risk of overfitting, and the danger of exposure to adversarial attacks.
Most of the challenges faced by today’s reinforcement learning (RL) algorithms, such as robustness, generalization, transfer, and computational efficiency, are highly correlated with compression — the minimizing of information by filtering out irrelevant data. Standard RL algorithms however lack explicit compression mechanisms.
In the new paper Robust Predictable Control, a research team from Carnegie Mellon University, Google Brain and UC Berkeley proposes a method for learning RL policies that use fewer bits of information. Their simple and theoretically-justified algorithm achieves much tighter compression, is more robust, and generalizes better than prior methods, achieving up to 5× higher rewards than a standard information bottleneck.

RL agents treat real-life problems as a sequence of decision-making problems, using salient information at one time step to predict salient information at the next time step. Therefore, compared to traditional data-hungry machine learning agents, the predictions of RL agents require less sensory information from the environment.
The researchers explain that if an RL agent can accurately predict the future, it will not need to consider as many bits of information from its future observations. Based on this idea, they propose Robust Predictable Control (RPC), a compressed RL method for learning policies that use fewer bits of information.
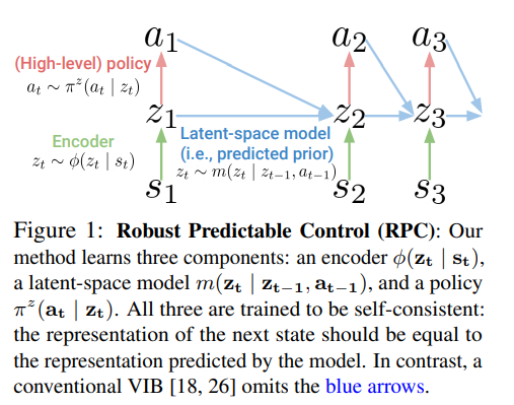
The proposed method advances on previous approaches by recognizing two important properties of the decision-making setting: 1) Learning a predictive model is not an ad-hoc heuristic, but rather a direct consequence of minimizing information using bits-back coding; 2) The agent can change the distribution over states, choosing behaviours that visit states that are easier to compress. In this way, the method can explicitly optimize for the accuracy of open-loop planning and results in a self-consistent model.
RPC unites concepts from information bottlenecks, model-based RL, and bits-back coding into its simple and theoretically-justified algorithm.
The researchers conducted a series of experiments with two objectives: 1) Demonstrate that RPC achieves better compression than alternative approaches, obtaining a higher reward for the same number of bits.; 2) Study the empirical properties of compressed policies learned by the proposed method, such as their robustness and ability to learn representations suitable for hierarchical RL.





The team compared RPC with an extension of the VIB that uses an LSTM (“RNN + VIB”), and evaluated compression performance on tasks from the OpenAI-Gym and image-based tasks from dm-control. They also tested the robustness of the compressed policies to different types of disturbances: missing observations, adversarial perturbations to the observations, and perturbations to the dynamics.
On almost all tasks, RPC achieved higher returns than prior methods for the same bitrate, learned more robust policies, and learned representations that were suitable for use in hierarchical RL. This improved compression and reliance on fewer bits of information can enable RL agents to better cope with high-dimensional sensory inputs, learn more broadly applicable representations, and be agnostic to idiosyncrasies in observations.
The paper Robust Predictable Control is on arXiv.
Author: Hecate He | Editor: Michael Sarazen, Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: r/artificial - [R] CMU, Google & UC Berkeley Propose Robust Predictable Control Policies for RL Agents - Cyber Bharat