
Since their introduction in 2017, transformer architectures have demonstrated tremendous performance and become the de-facto model for text understanding. Despite their proven power, transformers can also be inefficient and compute-heavy — as they suffer from quadratic complexity relative to input sequence length.
To address this issue, a team from Tsinghua University and Microsoft Research Asia has proposed Fastformer, an efficient transformer variant based on additive attention that achieves effective context modelling with linear complexity.

The team summarizes their contributions as:
- Propose an additive attention based transformer, Fastformer. To the best of our knowledge, Fastformer is the most efficient transformer architecture.
- Propose modelling the interaction between global contexts and token representations via element-wise product, which can help to fully model context information in a more efficient way.
- Extensive experiments on five datasets show that Fastformer is much more efficient than many transformer models and can achieve competitive performance.

The core of the transformer architecture is multi-head self-attention, which can capture the interactions between inputs at each pair of positions. This mechanism however results in a computational complexity that is quadratic to the sequence length. Instead of using the typical self-attention mechanism, the proposed Fastformer uses an additive attention approach to summarize the input attention query matrix into a global query vector. This novel mechanism models the interactions between global key and attention values via an elementwise product, and uses a linear transformation to learn global context-aware attention values. In this way, the contextual information can be effectively captured even as the computational complexity is reduced to linearity.
To evaluate the effectiveness of the proposed Fastformer, the researchers conducted extensive experiments on five benchmark datasets: Amazon, IMDB, MIND, CNN/DailyMail and PubMed. The team used glove embeddings to initialize a token embedding matrix, and applied an additive attention network to convert the matrix output by Fastformer into an embedding. For model optimization, they selected Adam, an algorithm for first-order gradient-based optimization of stochastic objective functions.
On classification tasks, the researchers measured accuracy and macro-F scores; on a news recommendation task, they reported AUC, MRR, nDCG@5 and nDCG@10 scores; and on text summarization tasks, they used the ROUGE-1, ROUGE-2 and ROUGE-L metrics to evaluate the generated summaries.
The team compared Fastformer performance with baseline methods such as the vanilla Transformer, Longformer, BigBird, Linformer, Linear Transformer and Poolingformer.
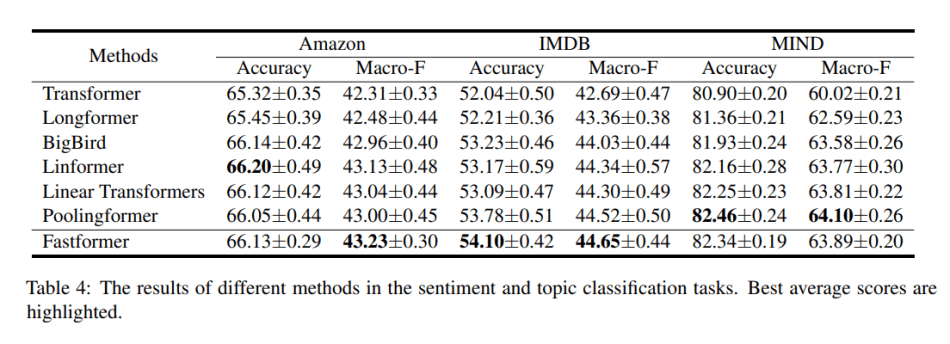

In the tests, Fastformer outperformed many existing transformer models and demonstrated its ability to achieve competitive or even better performance on long text modelling. Fastformer was also much more efficient than other linear complexity transformer variants in terms of both training and inference time.
In future work, the team plans to pretrain Fastformer-based language models to better empower NLP tasks with long document modelling; and explore additional applications that might benefit from Fastformer, such as e-commerce recommendation and Ads CTR prediction.
The paper Fastformer: Additive Attention Can Be All You Need is on arXiv.
Author: Hecate He | Editor: Michael Sarazen, Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: r/artificial - [R] Tsinghua U & Microsoft Propose Fastformer: An Additive Attention Based Transformer With Linear Complexity - Cyber Bharat
gooooooooooooood
goooooooooooooood
goooooooooood