
Baidu has released ERNIE 3.0, a framework for pretraining knowledge-enhanced language models that integrates both auto-encoder networks and auto-regressive networks. The novel approach achieves state-of-the-art results on Chinese and English language understanding and generation tasks.
Large-scale pretrained language models have achieved impressive results across many natural language processing (NLP) tasks, with state-of-the-art models like GPT-3 also demonstrating their strong task-agnostic zero-shot and few-shot learning capabilities. Most such models however are trained autoregressively on plain texts and without any knowledge enhancement, resulting in relatively weak performance on downstream language understanding tasks.
ERNIE 3.0 addresses this issue, presenting a unified pretraining framework that can easily be tailored for both natural language understanding and generation tasks with zero-shot learning, few-shot learning or fine-tuning.

The team summarizes their contributions as:
- Propose a unified framework ERNIE 3.0, which combines auto-regressive network and auto-encoding network so that the trained model can handle both natural language understanding and generation tasks through zero-shot learning, few-shot learning or fine-tuning.
- Pretrain large-scale knowledge enhanced models with 10 billion parameters and evaluate them with a series of experiments on both natural language understanding and natural language generation tasks. Experimental results show that ERNIE 3.0 consistently outperforms the state-of-the art models on 54 benchmarks by a large margin and achieves first place on the SuperGLUE benchmark.

ERNIE 1.0 (Enhanced Representation through Knowledge Integration) was introduced by a Baidu research team in April 2019. The model was designed to learn language representations enhanced by knowledge masking strategies that include entity-level masking and phrase-level masking. ERNIE 2.0, which debuted in July 2019, is a continual pretraining framework that incrementally builds and learns pretraining tasks through constant multi-task learning. The newly released ERNIE 3.0 builds on this, and can innovatively define a continual multi-paradigms unified pretraining framework that enables collaborative pretraining among multi-task paradigms.
The researchers were inspired by the architecture used in multi-task learning, in which a model’s lower layers are shared across all tasks, while the top layers are task-specific. ERNIE 3.0 thus enables various task paradigms to share the underlying abstract features learned in a shared network (universal representation module) and utilizes the task-specific top-level features learned in their own task-specific network (task-specific representation modules). Moreover, as it is based on ERNIE 2.0’s continual multi-task learning framework, ERNIE 3.0 can also effectively learn lexical, syntactic and semantic representations.
To evaluate the performance of ERNIE 3.0, the team compared their models with state-of-the-art pretraining models through fine-tuning on natural language understanding tasks, natural language generation tasks, and zero-shot learning. Experiments were conducted on 54 Chinese NLP tasks covering sentiment analysis, opinion extraction, text summarization, dialogue generation, etc.
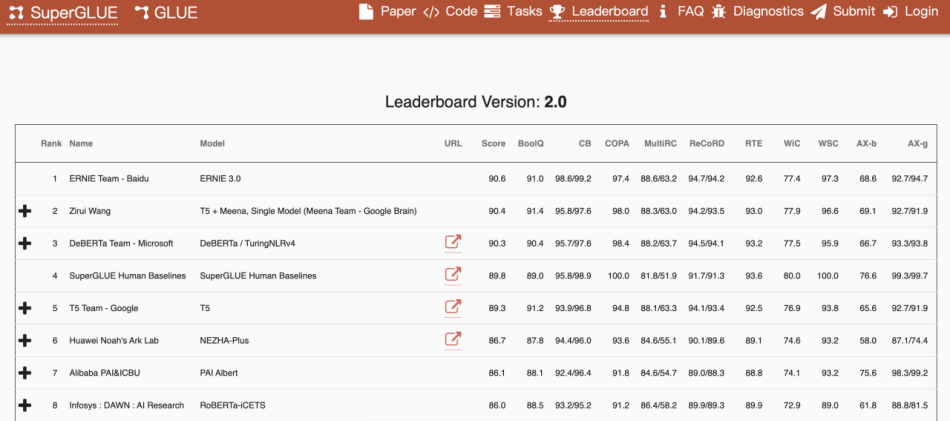




In the evaluations, ERNIE 3.0 achieved state-of-the-art results across all 54 Chinese NLP tasks it tackled. Its English-language version even surpassed human performance (90.6 percent vs. 89.8 percent) to take first place on the SuperGLUE language understanding benchmark.
The ERNIE 3.0 source code and pretrained models have been released on the project GitHub. The paper ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation is on arXiv.
Author: Hecate He | Editor: Michael Sarazen, Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: r/artificial - [R] Baidu’s Knowledge-Enhanced ERNIE 3.0 Pretraining Framework Delivers SOTA NLP Results, Surpasses Human Performance on the SuperGLUE Benchmark - Cyber Bharat
Pingback: [R] Baidu’s Knowledge-Enhanced ERNIE 3.0 Pretraining Framework Delivers SOTA NLP Results, Surpasses Human Performance on the SuperGLUE Benchmark : MachineLearning - TechFlx
Pingback: 15 August, 2021 11:40 – Notes de Francis