
Imagine you’re in an airport, searching for your departure gate. Humans have an excellent ability to extract relevant information from unfamiliar environments to guide us toward a specific goal. This practical conscious processing of information, aka consciousness in the first sense (C1), is achieved by focusing on a small subset of relevant variables from an environment — in the airport scenario we would ignore souvenir shops and so on and focus only on gate-number signage — and it enables us to generalize and adapt well to new situations and to learn new skills or concepts from only limited examples.
In a new study, a research team from McGill University, Université de Montréal, DeepMind and Mila that includes Turing Award honouree Yoshua Bengio draws inspiration from such human conscious planning to propose an end-to-end, model-based deep reinforcement learning (MBRL) agent that dynamically attends to only the relevant parts of its environmental state to improve its out-of-distribution (OOD) and systematic generalization.

Many existing MBRL methods rely on reconstruction-based losses to obtain state representations. While such an approach may be appropriate for robotic tasks with few sensory inputs, it struggles to deal with high-dimensional inputs, as the agent may focus on irrelevant obversions that are useless for reaching the goal. Moreover, the representations built by reconstruction loss may not help an MBRL agent plan and predict the desired signals. In their paper A Consciousness-Inspired Planning Agent for Model-Based Reinforcement Learning, instead of relying on reconstruction losses, the researchers build a latent representation jointly shaped by relevant RL signals without the use of a reconstruction loss.
Some MBRL agents also use explicit stages from their training, an approach that is more stable and easier to train. This process however relies on the environments where the initial exploration provides transitions being sufficiently similar to those observed under improved policies, which is not the case in many real-life scenarios. Furthermore, if these transitions do not contain reward information that can be used to update the input-to-representation encoder, the learned representations may not be reliable. The researchers therefore employ an end-to-end training process that enables the learning of the representation online and better adapts to non-stationarity in the transition distribution and rewards.
The team adopted simulation-based model-predictive control (MPC) for planning, a method that only updates the value function based on real data, effectively reducing the negative impact of model inaccuracies.

As previous work on representation learning for RL has shown that set-based representations are promising in capturing dynamics, the researchers utilize the compositionality of set representations to enable the discovery of sparse interactions between objects in the environment.
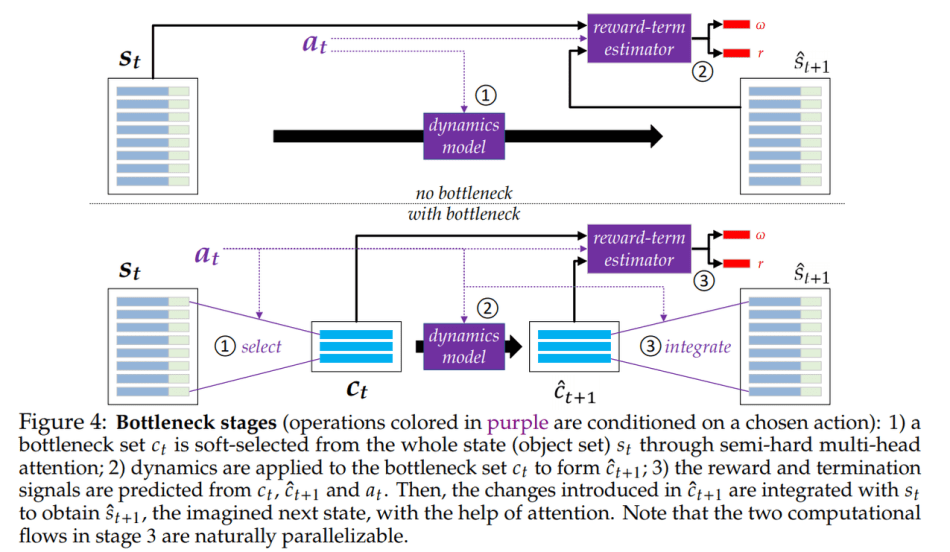
To improve generalization ability, the team introduces an inductive bias to mimic a C1-like ability in the planning agent. Basically, the planning focuses on a small set of relevant parts of the state of the environment, and simulations and predictions are performed on a bottleneck set containing all the important transition-related information.
The team explains their proposed Conscious Planning (CP) agent is expected to demonstrate the following abilities:
- Higher Quality Representation: The interplay between the set representation and the selection/integration forces the representation to be more disentangled and more capable of capturing the locally sparse dynamics.
- More Effective Generalization: Only essential objects for the purpose of planning participate in the transition; thus generalization should be improved both in-distribution and OOD because the transition does not depend on the parts of the state ignored by the bottleneck.
- Lower Computational Complexity: Directly employing transformers to simulate the full state dynamics results.
To evaluate their proposed CP agent on these expectations, the team conducted experiments comparing it against baselines (Unconscious Planning, model-free, Dyna, WM-CP, etc. ) to assess its OOD generalization and planning performance. The selected environments were based on the MiniGrid-BabyAI framework, and the experiments carried out on 8×8 gridworlds.



The team summarizes the results as:
- Set-based representations enable generalization across different environment dynamics in multi-task or non-static environments, forcing the learner to discover dynamics that are preserved across environments.
- Model-free methods face difficulties in OOD generalization.
- MPC-based planning exhibits better OOD generalization than Dyna-style algorithms.
- Online joint training of the representation with all the relevant signals is beneficial in RL.
- In accordance with the team’s intuition, transition models with bottlenecks learn dynamics better, likely because they prioritize learning the aspects most relevant, while models without bottlenecks tend to waste capacity on irrelevant aspects.
Overall, the results demonstrate that the proposed CP agent can plan effectively and improve both sample complexity and OOD generalization.
The paper A Consciousness-Inspired Planning Agent for Model-Based Reinforcement Learning is on arXiv.
Author: Hecate He | Editor: Michael Sarazen, Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: r/artificial - [R] Yoshua Bengio Team Designs Consciousness-Inspired Planning Agent for Model-Based RL - Cyber Bharat
Pingback: [R] Yoshua Bengio Team Designs Consciousness-Inspired Planning Agent for Model-Based RL : MachineLearning - TechFlx
Pingback: Note [142] Consciousness dimodelkan dengan algoritma Model-Based Reinforcement Learning (MBRL) – A Simple Notebook