
Autocompletion, where an application predicts the next item in a text input, has become a convenient and widely used tool in contemporary messaging and other writing tasks. It is also one of the most important features of an integrated development environment (IDE) for computer programming. Recent research has shown that autocompletion can be powered by deep learning, enabling software language models to achieve significant accuracy improvements by training on real-world datasets collected from programmers’ IDE activity. A common issue with less popular programming languages however is that the available IDE datasets may be insufficient for training.
In the paper Improving Code Autocompletion with Transfer Learning, a research team from Facebook shows how the power of transfer learning can enable pretraining on non-IDE, non-autocompletion, and different-language example code sequences before fine-tuning on the autocompletion prediction task. The proposed approach improves model accuracy by over 50 percent on very small fine-tuning datasets and over 10 percent on 50k labelled examples.

In software communities, a huge corpus of open-source code commits in all major programming languages is available on the GitHub repository. And there is no doubt that these code commits and the developers’ IDE activity have an intuitive relationship. It would therefore be beneficial if it were possible to use knowledge from these commits in modelling code authoring behaviours. As there are undeniably shared concepts and constructs that recur across all programming languages, the researchers propose transferring knowledge from the more popular programming languages to others where labelled data is insufficient.
The study’s datasets came from real-world developer activity at Facebook and focus on the popular programming language Python and the less popular language Hack. The team first trained a variety of monolingual models from either Hack or Python as well as several multilingual models from both languages. To effectively recognize and predict rare and novel tokens from an open vocabulary, they applied two tokenization approaches: Byte-pair encoding (BPE) and a Bigram encoding + copy mechanism. To test the effects of transfer learning they used two state-of-the-art code prediction performance models — GPT-2 and PLBART — and evaluated both online and offline model performance.


The team designed their extensive experiments to answer three questions:
- How do autocompletion models benefit from combining unsupervised pretraining with task-specific fine-tuning? How does their performance improve across offline and online evaluation?
- What is the effect of pretraining on a large source code dataset obtained from outside code authoring? Can pretrained software language models be fine-tuned on IDE autocompletion to achieve better accuracy with fewer real-world examples?
- Considering the case where a large training corpus is available in one language but not another, can pretraining a multilingual model on the language with more training data benefit the language with less data?
The team summarized their contributions and experimental findings as:
- Pretrain two transformer software language models GPT-2 and BART on source code files obtained from version control commits and show how their performance on autocompletion prediction improves through fine-tuning on real-world IDE code sequences by 2.18 percent.
- The GPT-2 model is trained on two real-world datasets: code sequences logged during IDE authoring and autocompletion selections. A third variant is pretrained on the former and fine-tuned on the latter corpus to demonstrate how the combination of pretraining and task-specific fine-tuning leads to a superior model, outperforming the base model by 3.29 percent.
- Show that pretraining on a different programming language boosts accuracy by 13.1 percent when comparing a model pretrained on Hack examples and fine-tuned on 10k Python examples versus only training on Python examples.
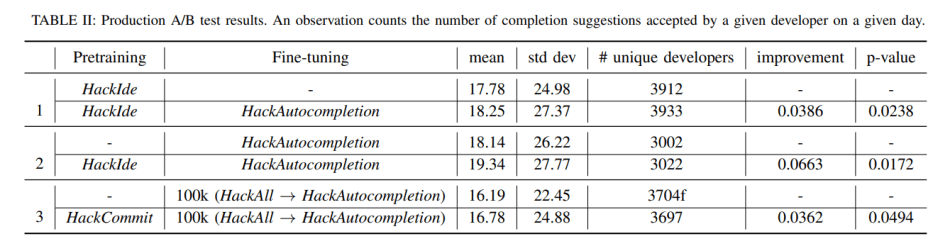
- Prove that improvements across these three transfer learning dimensions — task, domain, and language — translate into increased autocompletion tool usage by 3.86 percent, 6.63 percent, 4.64 percent respectively, by comparing these models through online A/B tests.
Overall, the study shows that pretraining autocompletion models on non-IDE, non-autocompletion and different language example code sequences can significantly improve model accuracy, indicating the potential of transfer learning to advance code autocompletion for less popular programming languages and improve the coding experience for developers who use them.
The paper Improving Code Autocompletion with Transfer Learning is on arXiv.
Author: Hecate He | Editor: Michael Sarazen, Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: [R] Facebook Transfer Learning Method Boosts Code Autocompletion Accuracy by Over 50% – ONEO AI
Pingback: r/artificial - [R] Facebook Transfer Learning Method Boosts Code Autocompletion Accuracy by Over 50% - Cyber Bharat