
OpenAI’s powerful GPT-3 large language model was a gamechanger in the machine learning community, and numerous illustrative demos have emerged since its June 2020 release. Debuild founder Sharif Shameem’s demo shows how GPT-3 lets users describe a desired layout in plain language, then sit back while the generator produces the appropriate JSX code.
The transformer-based GPT-3 has also proven a powerful solution across a variety of natural language processing (NLP) tasks, indicating the huge potential for NLP applications to process source code and crack software engineering tasks. This promising direction has however remained relatively under-explored. Until now.
In the new paper CodeTrans: Towards Cracking the Language of Silicone’s Code Through Self-Supervised Deep Learning and High Performance Computing, a research team from Technical University of Munich, Google, Nvidia and LMU München propose CodeTrans, an encoder-decoder transformer model that achieves state-of-the-art performance on tasks in the software engineering domain.

Software engineering is the highly complex process of designing, implementing, testing and maintaining information systems. Programming languages — machine understandable language for engineers to communicate with computers — are central to the software engineering process. The researchers propose that NLP techniques can also be applied to solve programming language tasks and assist in the software engineering process.
The proposed CodeTrans adapts the encoder-decoder model proposed by Vaswani et al. (2017) and the T5 framework implemented by Raffel et al. (2020). Unlike the T5 models, the proposed approach disables
the reduce_concat_tokens feature, so that every sample will have only a single training example rather than concatenating different training examples up to the maximum training sequence length. The team also borrows the TaskRegistry and MixtureRegistry concepts from T5 models. Each task can be built as one TaskRegistry, and one or more TaskRegistries can build one MixtureRegistry. In all, the researchers build 13 TaskRegistries, one MixtureRegistry for self-supervised learning, and another MixtureRegistry for multi-task learning.
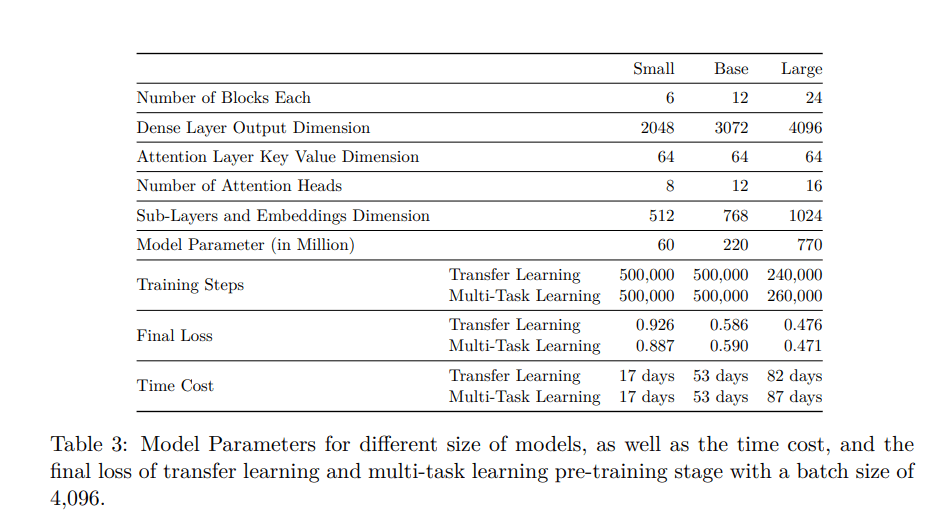
The researchers trained CodeTrans using single-task learning, transfer learning and multi-task learning on one NVIDIA GPU and Google Cloud TPUs, using both supervised tasks and self-supervised tasks to build a language model in the software engineering domain.
They applied the proposed CodeTrans on six supervised tasks in the software engineering domain: Code Documentation Generation, Source Code Summarization, Code Comment Generation, Git Commit Message Generation, API Sequence Recommendation, and Program Synthesis.
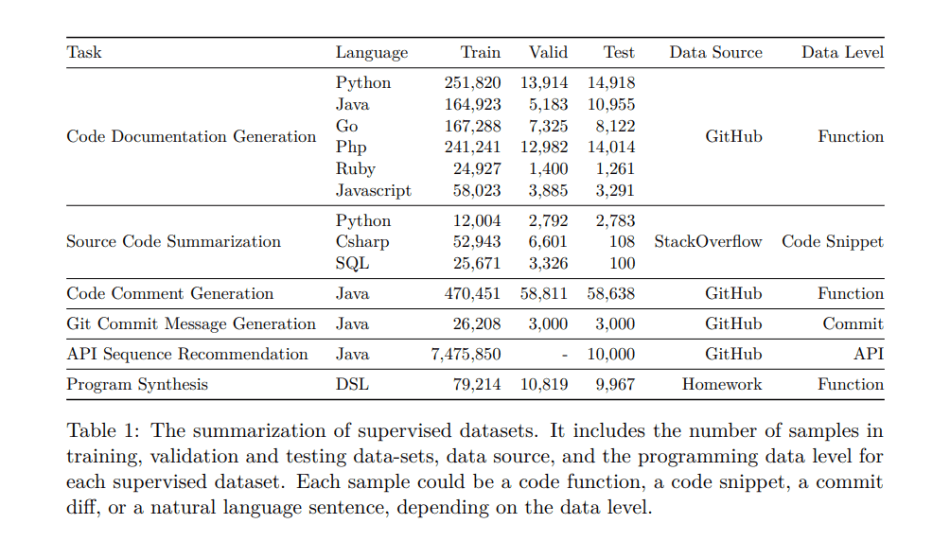
The Code Documentation Generation tasks require a model to generate documentation for a given code function. The task contains six programming language functions, including Python, Java, Go, Php, Ruby, and Javascript. The Source Code Summarization task aims to generate a summary for a short code snippet, and involves Python, SQL, and CSharp languages. Code Comment Generation focuses on generating the JavaDoc for Java functions. The task Git Commit Message Generation aims to generate a commit message describing the git commit changes. API Sequence Recommendation is used to generate the API usage sequence, such as the class and function names based on a natural language description. Program synthesis meanwhile is the task of synthesizing or generating programming codes based on natural language descriptions.

All tasks were evaluated on a smoothed BLEU-4 score metric. For Code Documentation Generation, CodeTrans outperformed CodeBert on all the programming languages. It also outperformed Code-NN in Source Code Summarization tasks. For Code Comment Generation, CodeTrans surpassed DeepCom by more than one percent on the smoothed BLEU score. For Git Commit Message Generation, CodeTrans outperformed the NMT models, and the performance of the CodeTrans multi-task learning large model was close to the transfer learning large model. For API Sequence Recommendation, the CodeTrans large model with multi-task learning fine-tuning achieved the highest scores of all models. And for Program Synthesis, nine out of ten CodeTrans models outperformed the Seq2Tree model.
The CodeTrans models outperformed all baseline models, achieving state-of-the-art performance across all tasks.
The team says the study shows that larger models can bring a better model performance, models with transfer learning perform as well as models with multi-task learning fine-tuning, and pretraining models can be fine-tuned on new downstream tasks efficiently while saving a significant amount of training time. The results indicate the promising potential of applying transformer encoder-decoder architectures to the software engineering field.
The CodeTrans code is available on the project GitHub. The paper CodeTrans: Towards Cracking the Language of Silicone’s Code Through Self-Supervised Deep Learning and High Performance Computing is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: [N] TUM, Google, Nvidia & LMU München’s CodeTrans Pretrained Models Crack Source Code Tasks With SOTA Performance – ONEO AI
Pingback: TUM, Google, Nvidia & LMU München’s CodeTrans Pretrained Models Crack Source Code Tasks With SOTA Performance – Njxxllc
Pingback: r/artificial - [N] TUM, Google, Nvidia & LMU München's CodeTrans Pretrained Models Crack Source Code Tasks With SOTA Performance - Cyber Bharat
We are currently looking for a similar solution on the engineering platform https://engre.co/ that can help our business. However, such automation and technologies cost a lot, and development is often needed, which can take time.