
Today’s large language models have greatly improved their task-agnostic, few-shot performance, with top models like GPT-3 competitive with state-of-the-art finetuning approaches when provided only a few examples in a natural language prompt. This few-shot, “in-context” learning approach is gaining traction in large part due to its ability to learn without parameter updates. Compared to traditional finetuning methods, few-shot learning enables practitioners to more quickly prototype NLP models, allows non-technical users to create NLP systems, and efficiently reuses models to reduce system memory and complexity.
GPT-3’s accuracy however can be highly unstable across different prompts (training examples, permutation, format). To address this, a new UC Berkeley, University of Maryland and UC Irvine study sets out to identify the pitfalls that can cause instability in the GPT-3 language model and proposes a contextual calibration procedure that consistently improves GPT-3 (and GPT-2) accuracy across different prompt format choices and examples.

Typically, a natural language prompt is fed to neural autoregressive language models to ensure they perform few-shot learning using in-context learning. The prompt consists of three components: a format, a set of training examples, and a permutation of the training examples.
The researchers first studied how GPT-3’s accuracy changes across different prompts. They conducted sentiment analysis task experiments on three GPT-3 model sizes (2.7B, 13B, and 175B parameters) trained on SST-2 datasets, and observed high variance in GPT-3’s accuracy across the prompts’ training examples, permutation of examples, as well as format. Surprising, varying the permutation of the training examples could cause accuracy to range from 54.3 percent to near state-of-the-art (93.4 percent).
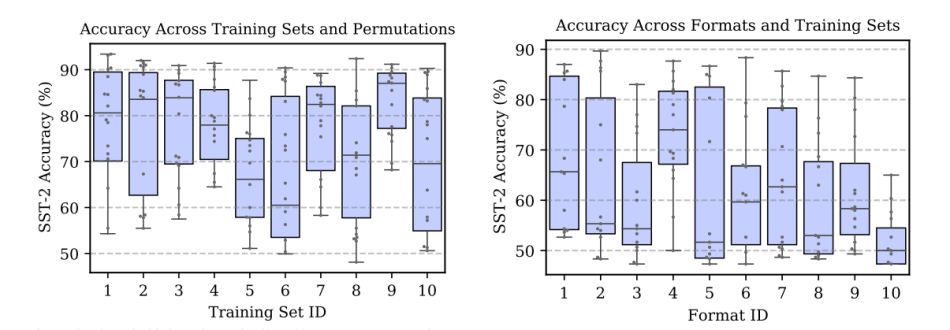
The researchers next analyzed factors that contribute to GPT-3 instability, identifying three biases behind the accuracy variance:
- Majority Label Bias GPT-3 is biased towards answers that are frequent in the prompt. The majority label bias helps explain why different choices for the training examples heavily influence GPT-3’s accuracy — as this shifts the distribution of model predictions.
- Recency Bias The model’s majority label bias is aggravated by its recency bias: the tendency to repeat answers that appear towards the end of the prompt. Overall, recency bias helps to explain why the permutation of the training examples is important.
- Common Token Bias GPT-3 is biased towards outputting tokens that are common in its pretraining distribution. The common token bias helps explain why the choice of label names is important, and why the model struggles with rare answers.
The team says these three biases together tend to contribute to a simple shift in a model’s output distribution.
Inspired by the idea that model biases towards certain answers can be estimated by feeding content-free inputs, the researchers proposed a novel data-free contextual calibration procedure to infer parameters. To evaluate the contextual calibration’s effectiveness, they conducted experiments on text classification, fact retrieval and information extraction tasks across different datasets (AGNews, MIT Director, DBPedia, TREC etc.).
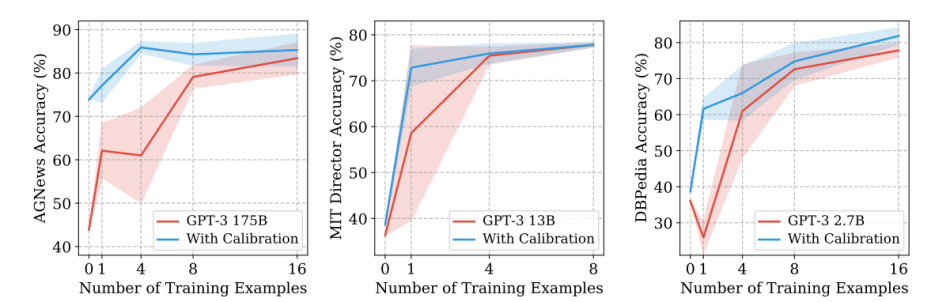

The proposed contextual calibration method improves the accuracy and reduces the variance of GPT-3 models, boosting average and worst-case absolute accuracy by up to 30 percent. The study highlights the need for better understanding and analysis of the dynamics of in-context learning.
The paper Calibrate Before Use: Improving Few-Shot Performance of Language Models is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: [N] New Contextual Calibration Method Boosts GPT-3 Accuracy Up to 30% – ONEO AI
Pingback: New Contextual Calibration Method Boosts GPT-3 Accuracy Up to 30% – ONEO AI