
Big RNNs Achieve SOTA Performance in Video Prediction
It’s not as easy as one might imagine to train an AI model to accurately predict what a human will do next, even when they are interacting with a relatively simple object like a ball.
AI Technology & Industry Review
It’s not as easy as one might imagine to train an AI model to accurately predict what a human will do next, even when they are interacting with a relatively simple object like a ball.

The Seventh International Conference on Learning Representations (ICLR) kicked off today. One of the world’s major machine learning conferences, ICLR this year received 1591 main conference paper submissions — up 60 percent over last year — and accepted 24 for oral presentations and 476 as poster presentations.

According to an AWS blog post, Apache MXNet now supports Keras 2 and the Keras-MXNet deep learning backend is now available to developers.

Researchers from the British AI company yesterday published a paper on Nature — Vector-based navigation using grid-like representations in artificial agents — which proposes an artificial virtual agent that can navigate like mammals.

Cambricon today unveiled its Cambricon 1M chip for edge computing, and the MLU100, the first in a new chip series for cloud computing.

To boost CNN performance, industry leaders and startups alike are now racing to develop specialized AI chips.

Much like that epoch-making event 28 years ago, AI technology is breaking down limitations and opening up new opportunities.

This paper gives a demonstration of using Bayesian LSTMs for classification of medical time series, which can improve the accuracy compared with standard LSTMs.

Facebook AI Researcher Yuandong Tian says new AlphaGo Zero paper is destined to be a classic.

Attention is simply a vector, often the outputs of dense layer using softmax function.

In the article “Memory, attention, sequences”, the author predicts that future work on neural networks will emphasize understanding complex spatio-temporal data from the real world, which is highly contextual and noisy.

This paper proposes not only a method as a useful tool but also a new concept for modeling complex annotation as a simple polygon.

Compared to SMT, NMT can train multiple features jointly and does not need prior domain knowledge, enabling zero-shot translation. In addition to higher BLEU score and better sentence structure, NMT can also help reduce morphology errors, syntax errors, and word order errors of SMT.

We interviewed Mr. Qiang Dong, chief scientist of Beijing YuZhi Language Understanding Technology Co. Ltd. and learned more about their YuZhi NLU Platform that conducts its unique semantic analysis based on concepts rather than words.

The paper proposes a hybrid neural machine translation model concerning both words and characters, which mainly contributes to the translation of rare or unknown words.

Although no innovations for the NMT architecture was introduced, the authors claim that a classic NMT baseline system with carefully tuned hyperparameters can still achieve comparable result to the state-of-the-art.

This repository did some toy experiments based on Tensorflow in order to introduce some deep learning concepts which are used for image recognition and language modeling.

In order to deploy Recurrent Neural Networks (RNNs) efficiently, we propose a technique to reduce the parameters of a network by pruning weights during the initial training of the network.

This talk was recently given by Prof. Christopher Manning at Simons Institute, UC Berkeley. It is an introductory tutorial without complicated algorithms.
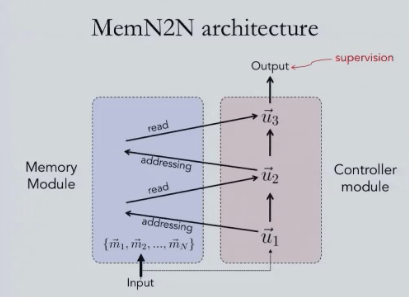
The team of Rob Fergus, who is currently a research scientist at Facebook AI Research, have devised two neural net models for handling unstructured data.

This talk summarizes the limitations of RNN (including LSTM, GRU), from both empirical and computational hierarchy mechanism perspectives.