Rob Fergus, New York University / Facebook
w/ Sainbayer Sukhbaatar, Arthur Szlam
Video Source: http://www.fields.utoronto.ca/video-archive/static/2017/01/2267-16463/mergedvideo.ogv
Introduction
With decades of development, we now have some models that work quite well with some data structures. For example, we have RNN for temporal structure, and Convolutional Network for spatial structure. However, people are still struggling with some specific types of data structure and dependencies.
These annoying problems involve out-of-order access, long-term dependency, unordered set, and changes in input/output size. For example, machines are having trouble extracting key concepts from a narrative story, because the sentences and logic are out-of-order; they also have a barely satisfactory performance on traffic junction control problem, especially with limited visibility, because the inputs keep changing.
Recently, the team of Rob Fergus, who is currently a research scientist at Facebook AI Research, have devised two neural net models for handling unstructured data. Built on top of some existing models with creative modifications, these models manifest a strong adaptation on some problems that would confuse traditional models.
One of their new models is “End-to-End Memory Network” (MemN2N), which adopts a serial approach; another is called “Communication Neural Network” (CommNN), which uses a parallel approach instead. We will go through these two models separately, getting a sense of their structure and how components of the model work together to figure out the best output.
Memn2n Network
Overview
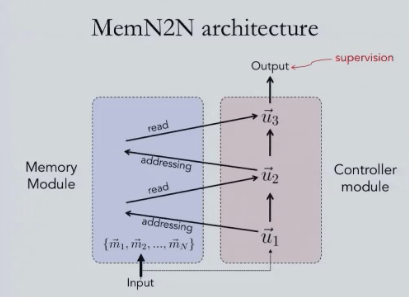
A MemN2N network consists of two major components: a controller module, and a memory module. The input to this model is a set of vectors, with one vector per datapoint. The controller module performs multiple sequential lookups (hops) into memory module, which includes reading from memory with soft attention, and end-to-end training with back-propagation.
MemN2N architecture
As mentioned above, a MemN2N has two separate pieces: a controller module, and a memory module. A set of unordered memory vectors is sent as input to the memory module, while the controller takes an initial state vector to begin with. The addressing process uses vector in the controller to access different locations in the memory, and the corresponding memory vector will be added to the previous controller vector, so the old vector gets updated. This process continues for a fixed number of times, and send out discrete outputs in the end. During the whole process, the only place to have supervision is that of the output.
This process is different from RNN in that it does not complete the procedure in a “hidden state”, which is unlikely to memorize information through a complete time interval.
Memory Module – a closer look
In the addressing phase, the input vectors are taken dot product with the Controller vector, and their softmax will be taken to form a set of attention weights (or soft addresses). The reading phase then takes probability vectors and input vectors to get a weighted sum. This signals one round of a “hop” in the Memory Module, and the weighted sum will then be added to controller state.

To explain this on real examples, consider playing a “Question and Answering” game: Some logically related sentences are given, and then a question is raised based on the sentences.
In the example below, input vectors are constructed with Bag-of-Words (BoW); you can also add time embedding to form a kind of temporal structure. During the training process, the correct answer can be back-propagated through the model, so that it can move around the memory vectors such that it produces the correct answers.

Compared with RNN, MemN2N essentially takes one single input and produces one output rather than having multiple inputs recurrently. The recurrent process in RNN is pretty much replaced by the “hops” inside the Memory Module.
Performance
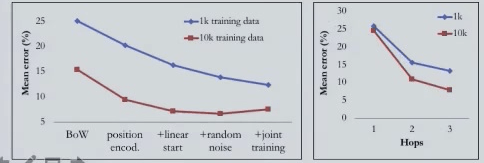
Rob’s team tested this model on the 20 bAbI tasks [Weston et al. 2015]. The task is to answer questions after reading a short story, and different tasks require different reasoning. Sentence are short, with a small vocabulary, and simple language.
Compared with the training process in the paper of Weston et al., which also supervises the memory access in addition to the output, the best performance of this model on 10k data is quite close to the strongly supervised, while only has supervision over the output.

It is worth noting that different sentence representations and training processes also affect the performance, as well as the number of hops allowed in the Memory Module.
Attention during memory hops
The “hops”, which are discrete accesses in the memory module, are a key factor in determining the whole model’s performance. With more hops, the attention will get closer to the final sentence that leads to the correct answer. The changes of attention through hops are quite similar with the way human do induction step by step from the sentences. Below illustrate two examples:

The pattern of memory attention during hops is also quite interesting. Among all the words in the previous sequence, it focuses on the most recent word in the first hop, but has an average attention through all previous words during the second hop, and this pattern repeats for the following hops. The picture below illustrates this point. Brighter area indicates heavier attention, and positions to the right are more recent ones.

MemN2N Summary
As we have seen, the MemN2N model that Rob is using here has some noticeable characteristics. First, its input data is pre-loaded in memory, and is accessed in arbitrary order. Second, it performs serial access to the memory over time. Third, it employs end-to-end training with back propagation. Rob also notes that, to extend this model, one can develop a writable memory, or apply it to games together with reinforcement learning models.
Communication neural network
Overview
The CommNN is drastically different from the other model. It is composed of separate neural networks as streams, and each data point has its own processing stream. The model performs continuous broadcast communication channel between streams, while streams must learn to communicate to solve a task. For the training process, streams need to learn Multi-agent Communication with Back-propagation.
CommNN model structure
As shown in the figure below, CommNN has a parallel structure sets of streams. Each data point is converted to a stream through an embedding function, and each embedding will pass through a neural net module (does not matter what neural net it is).
What links the streams is a sequence of communication hops between them. In each hop, the hidden states of the streams will be propagated as inputs to the modules of the next hop. Each module receives two inputs: the first one is the hidden state of the previous module; the second one is a value distributed from the communication channel during the hop, which sums all the hidden states.

In fact, this conversion of hidden states during one single hop can actually be seen as one matrix operation:

While it is obvious MemN2N and CommNN are very different in many aspects, the difference between the process of approaching best output is our biggest interest. In MemN2N, there are sequential accesses between the controller and memory modules to find the best answer, while in CommNN, the process is parallel, with distributed streams and no central controller. In CommNN, all streams need to “chat” with each other to figure out the correct answer.
Apply with CommNN
“bag to sequence” game – It turns out the model is also able to deal with “bag to sequence” problem, which is to arrange a set of words into correct order to form a meaningful sentence. With 2 hops, Gigaword, 5 words, 2 layer MLP one stream, the error per word of this model is 26%, compared with 40% of 5-gram by KenLM.(http://kheafield.com/code/kenlm/)
Traffic junction control – A natural setting for CommNN is Reinforcement Learning. In a multi-agent reinforcement learning, each stream of CommNN is an agent, and agents collaborate to solve a given task. The reward from the environment is shared equally by these agents. It turns out that this application works pretty well on problems like traffic junction control. Rob played a couple of demos on this. Below is the comparison of performing the task with and without the model, and the influence of choosing different ways of communication.

How do agents communicate?
You may wonder, how do agents in CommNN actually “communicate”? What pattern do they perform? Is this structure reasonable?
In the traffic junction control experiment, it turns out that not all agents are giving off messages all the time. Instead, from the PCA(Principal component analysis) graph, we can see that majority of the agents are quiet for the most of time, waiting for message from other agents, while there are small groups of agents sending out messages from time to time (cluster A, B, and C). The graph of corresponding hidden vectors verifies this pattern.

CommNN Summary
It is worth noting that CommNN is a distributed NN model, which means it is more appropriate for tasks where input and output are sets. Moreover, the models learn sparse communication protocol. To further extend the model, one can combine it with RL for MARL problems. If you check the original video, Rob has more detailed explanations and examples on how he actually tried those applications, and how the results were.
Related Paper/Resources ( Suggested Readings )
- MemN2N:
- End-to-end Memory Networks(MemN2N): Sainbayar Sukhbaatar et al.( https://arxiv.org/abs/1503.08895)
- Hard Attention Memory Network [Weston et al. ICLR 2015]
- RNN search [Bahdanau et al. 2015]
- Recent works on external memory:
- Stack memory for RNNs [Joulin & Mikolov. 2015]
- Neural Turing Machine [Graves et al. 2014]
- Early works on neural network and memory
- [Steinbuch & Picke. 1963]
- [Taylor. 1959]
- [Das et al. 1992]
- [Mozer et al. 1993]
- Concurrent works
- Dynamic Memory Networks [Kumar et al. 2015]
- Attentive reader [Hermann et al. 2015]
- Stack, Queue [Grefenstette et al. 2015]
- Sequence to sequence [Vinyals et al. 2015]
- CommNN:
- Graph Neural Networks
- Gori et al., IJCNN 2005;
- Scarselli et al., IEEE Trans. Neural Networks, 2009
- Gated Graph Neural Networks
- Li, Zemel, Brockschmidt & Tarlow, ICLR 2016
- Concurrent work
- Foerster et al. [NIPS 2016]
- Graph Neural Networks
Analyst: Shari Sun | Localized by Synced Global Team : Xiang Chen
0 comments on “Let Neural Networks to Memorize and Communicate”