
This talk was recently given by Prof. Christopher Manning at Simons Institute, UC Berkeley. It is an introductory tutorial without complicated algorithms. The topic is divided into four parts:
- Human language characteristics
- Distributed word representation
- State of art bi-directional LSTM
- Some RNN applications
Talk Link: https://www.youtube.com/watch?v=nFCxTtBqF5U
PDF: https://simons.berkeley.edu/sites/default/files/docs/6449/christophermanning.pdf
Human language characteristics
One of the most distinctive characteristics of human language is its meaningful representation. No matter what a human says, be it a word or a phrase, it tends to have its own meaning. Human language also has a special structure that makes it easy to learn, such that even a child can quickly grasp it. Different from the necessary inputs used in the state-of-the-art machine learning methods, human language is more likely to be a discrete/symbolic/categorical representation. Therefore, we need a more efficient and meaningful way to encode human language.
Distributed word representation
WORD VECTOR
In terms of some traditional machine learning approaches, a word is represented as a discrete vector in the vector space (i.e. one-hot coding), for example: [0 0 0 0 1 0 0 1]. It could be that a big vector has the same size of a big vocabulary. But one problem of this approach is the lack of natural notion of similarity, i.e. if we want to search for “Dell notebook”, we could also accept the term “Dell laptop”, but they are in fact represented as two different discrete vectors, [0 0 0 1 0] and [0 0 1 0 0]. Due to orthogonality, we cannot build any concept connections between them.
In order to share more statistics and to seek for more similarities between the similar words and phrases, a dense vector was proposed, which has been regarded as one of the most successful ideas of modern NLP. Neural nets uses dense vector for word representation.
DETAILS OF WORD2VEC
In neural networks, a standard probabilistic modelling for learning a dense word vector is based on the following formula:
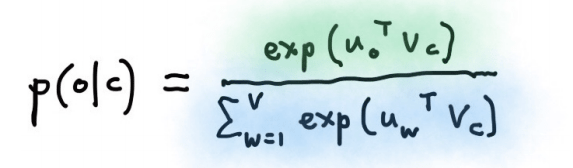
It means the objective is defined as a softmax using a center word c and its context words, where o is the context words index and u_o is the corresponding word vectors, c is the center word index and v_c is the corresponding word vector. The overall goal is try to maximize this probability so after a million back-propagation, the words with the same surrounding word vectors tend to have similar meanings in the vector space.

The above picture is the projected word vectors in the vector space after learning. As a result, not only can it capture kind of similarity co-occurrence, but also capture some fine-grained dimensional meanings so you can observe some special contextual connections in some specified directions.
Current state of art BiLSTM
“Basically, if you want to do a NLP task, no matter what it is, what you should do is throw your data into a bi-directional long-short term memory network, and augment its information flow with attention mechanism.” – Chris.D.Manning.

The above picture is the classic RNN encoder-decoder network. At first, the encoder network read-in words of source sentence at each time step, and the corresponding hidden state is calculated based on the current input and previous hidden state. Then, the decoder begins to generate words based on the last hidden state of the encoder. Unfortunately, it does’t work as well as machine translation, because it cannot capture the long time dependency of the source sentence.
For improvement, LSTM and GRU were proposed. They are two of the most successful RNN variations in recent years to solve the long time dependency problem. They are also widely called the “gated recurrent units”. The gating mechanism controls which information should be passed to the next step so a good translation can be predicted.

The above picture is the mathematical formula for a GRU module. A GRU module is like a reading/writing register. It reads part of the previous hidden state, combine with current input to construct the candidate update (see second row in the above formula). Then it keeps part of the dimension the same as previous hidden state, and update the remaining part by candidate update (see the first row in the above formula). Note u_t and r_t are multi-variate Bernoulli distribution which ranges from 0 to 1 (in order to make a choice: forget or update).

The LSTM module is quite similar to GRU module, but with more trainable parameters. The idea here is also a candidate update value based on previous hidden states and current input (see 3rd equation in the above formula). It is used for cell calculation (see 2nd equation in the above formula). When we calculate the cell, part of the previous cell state might be forgotten based on f_t, and part of the candidate update can be added depending on the i_t. After the cell state be calculated, the current hidden state can be calculated based on the cell and an output gate. (see 1st equation in the above formula). Note that f_t and i_t are also multi-variate Bernoulli distribution which ranges from 0 to 1 (in order to make a choice: forget or update).
The magic here is the “+” sign (see 1st equation in the above GRU formula and 2nd equation in the above LSTM formula). It will integrate new candidate neural hidden states with part of the hidden states at previous time-steps, which means the information flow can be carried through multiple direction based on the previous step. This way, the gradient will be back-propagated more smoothly (less gradient vanishing problem), and the system tends to have a longer short-term memory compared to the classic recurrent neural network.
In summary, based on the gates control, the LSTM/GRU module can be focused on some specified context and forget context contributes less in the future, so overall it can memorize part of the sentence for a while in order to contribute to the future learning process.

Here is the LSTM encoder-decoder structure proposed by Sutskever et al. 2014 [1], which has been examined with outstanding performance for machine translation. The LSTM module is substituted to each units inside the network, with a deeper architecture. The workflow is the same as before: read-in the source sentence, encode it into hidden embeddings, then generate the sentence by a decoder. But there is still a big limitation here: The entire memory is sent to the decoder and is linked to the final step of the encoder. This architecture could also trigger two problems: first, the information flow could be limited this way. Second, with a longer sentence, the tokens at the beginning of the encoder might be forgotten when it goes from left to right.

To overcome these two problems, Bi-LSTM with attention is proposed. The idea of attention mechanism is during one step in the decoder, it gives an additional level of control, based on a context vector which takes care of the whole information from the source sentence (look back to the source sentence and calculate how relevant they are between each encoder hidden state and current decoder hidden state). With the weighting, the context vector can influence the hidden state of the current decoder based on entire source sentence, rather than only the final encoder hidden state, which can augment the memory and make it extremely successful in practice. In order to better represent the source sentence, a bi-directional design is used in the encoder by not just running the LSTM in one direction, but run it in both directions. That helps the model build a better representation for each word in the source sentence by using the right context and left context. In practice, when you get the word vector for each word based on each direction, just concatenate them and it always gives a bit of improvement (both on final accuracy and syntactic ordering).

In recent years, neural MT (NMT) has made significant progress on WMT latest evaluation compared to traditional phrase-based mt and syntax-based mt. There are four advantages of NMT:
- End-to-end training: to allow the parameters be optimized simultaneously
- Distributed word representation: for better mining phrase similarities
- Bigger context: can generalize well for bigger context (the bigger the better)
- More fluent in text generation: the text generation has better syntax meaning
Some RNN applications
There are various applications based on RNNs, e.g. question answering, reading comprehension and sentiment analysis, etc. Recently, some people also use convolutional neural network for machine translation [2].
Some Reviewer’s thoughts
Although neural based approach makes a significant progress on WMT latest evaluation, in practice, especially in terms of real-word in-domain data, NMT could still not be as competitive as statistical based MT. On the one hand, I hope people can build more meaningful, comprehensive, and various types data for NMT system development, on the other hand, in terms of NLP, no matter what the specific task is, more structure and modularity for language and memory is always needed, especially for generalization ability and interpretability.
References
[1] Sequence to Sequence Learning with Neural Networks, Ilya Sutskever, Oriol Vinyals, and Quoc Le, NIPS 2014
[2] Convolutional Sequence to Sequence Learning, Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin, arXiv preprint arXiv:1705.03122v1, 2017.
Author: Shawn Yan | Localized by Synced Global Team: Junpei Zhong
The exploration of language representations from words to sentences was incredibly illuminating. Prof. Christopher Manning tutorial seems like a comprehensive dive into various language facets.
Best Commercial Window Tint Services in Opelika AL