
StarCraft II is one of the most challenging Reinforcement Learning (RL) environments, it requires RL agents to have smart strategic planning over long time horizons with real-time execution.
While online Reinforcement Learning (RL) algorithms have achieved great success by training on the challenging environments, most real-world applications requires RL agents to learn in the offline setting, which demands on more challenging offline RL benchmark for agents training.
In a new paper AlphaStar Unplugged: Large-Scale Offline Reinforcement Learning, a DeepMind research team presents AlphaStar Unplugged, an unprecedented challenging large-scale offline reinforcement learning benchmark that leverages a offline dataset from StarCraft II for RL agents training, and its baseline offline agent achieves 90% win rate against previous state-of-the-art AlphaStar supervised agent.

The team considers StarCraft II as a two-player game that combines high-level reasoning over long horizons with fast and delicate unit management. It is suitable for benchmarking offline reinforcement learning algorithms due to abundant replays for training agents and easy evaluation method by playing against humans.
The proposed AlphaStar Unplugged is built upon the StarCraft II Learning Environment and associated game replays. The researchers summarizes their key contributions as follows for building a challenging offline RL benchmark:
- Training setup. We fix a dataset and a set of rules for training in order to have fair comparison between methods.
- Evaluation metric. We propose a set of metrics to measure performance of agents.
- Baseline agents. We provide a number of well tuned baseline agents.
- Open source code. Building an agent that performs well on StarCraft II is a massive engineering endeavor. We provide a well-tuned behavior cloning agent which forms the backbone for all agents presented in this paper.
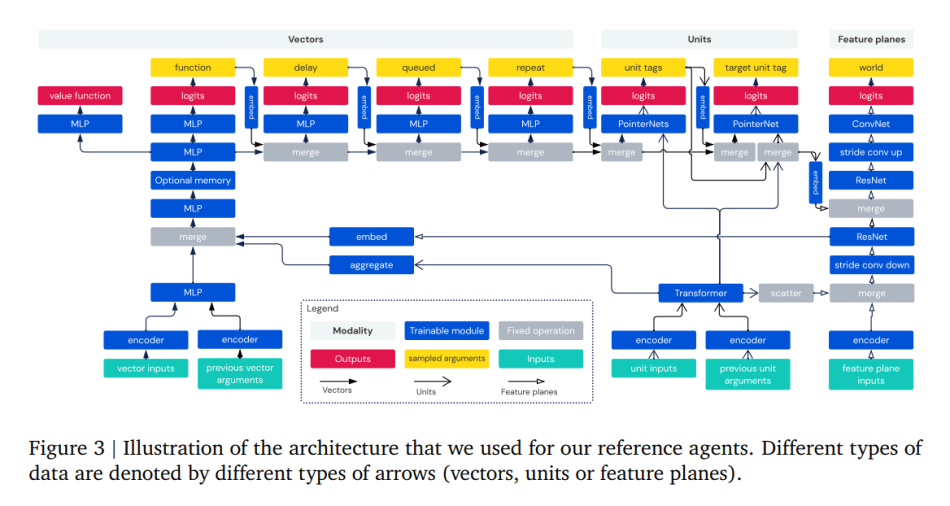
The team also provides 6 reference agents to be used as baselines and for evaluation metrics. In the agent architecture, inputs of the raw StarCraft II API consist of three modalities: vectors, units and feature planes; actions consist of seven modalities: function, delay, queued, repeat, Unit_tags, target_unit_tag and world action.
They use MLP to encode and process the vector inputs, transformer for the units input and residual convolutional network for the feature planes. To add interactions between these modalities, they scatter units into feature planes, embed the units into the embedded vectors, embed feature planes into vectors using strided convolutions and reshaping and do the reverse operation to embed vectors back to feature planes. Moreover, they use memory in the vector modality, a value fucntion for the experiments and sample actions.


The empirical results show that offline RL algorithms achieve 90% win rate against the previously published AlphaStar Supervised agent by using only offline data. The team believes their work will be valuable for large-scale offline reinforcement learning research.
The paper AlphaStar Unplugged: Large-Scale Offline Reinforcement Learning on arXiv.
Author: Hecate He | Editor: Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: DeepMind’s AlphaStar Benchmark Improves RL Offline Agent With 90% Win Rate Against SOTA AlphaStar Supervised Agent – Ai Headlines