
Recent advancements in Large Language Models (LLMs), pretrained on extensive web-based datasets, have endowed these models with a broad spectrum of novel capabilities through in-context learning, including the ability to direct robot behaviors.
However, LLMs often falter when tasked with guiding low-level robot actions due to the dearth of relevant training data.
Addressing this issue, Google DeepMind’s research team introduces a approach in a new paper Language to Rewards for Robotic Skill Synthesis. This novel paradigm leverages reward functions to bridge the gap between language and low-level robot actions,. It empowers non-technical users to instruct intricate robot actions without the need for massive data or expert knowledge to engineer low-level primitives.

This work is motivated by the idea that instead of connecting instructions with low-level actions, it would be better to connect them to rewards due to their richness of semantics. Moreover, reward terms are normally modular and compositional, which makes them easier to to represent complex behaviors, goals, and constraints more concisely.

One challenge to realize the abovementioned idea is to design good rewards, which usually requires extensive domain expertise in pervious approaches. To address this issue, the team proposes to utilize LLMs to automatically generate rewards and leverage online optimization approaches, which is MuJoCo MPC, a real-time optimization tool that optimizes the generated reward functions to synthesize robot behavior. As a result, even non-technical users are able to generate and steer robots behaviors without large training data or expert knowledge.

More specifically, the proposed system takes instructions in natural language from uses as inputs and synthesizes corresponding robot motions through reward function. It consists of two key components: 1) a Reward Translator, a pre-trained LLM-based model that interacts with and understands user intents and modulates all reward parameters and weights; 2) a Motion Controller that consumes the generated reward and interactively optimize the robot motions.
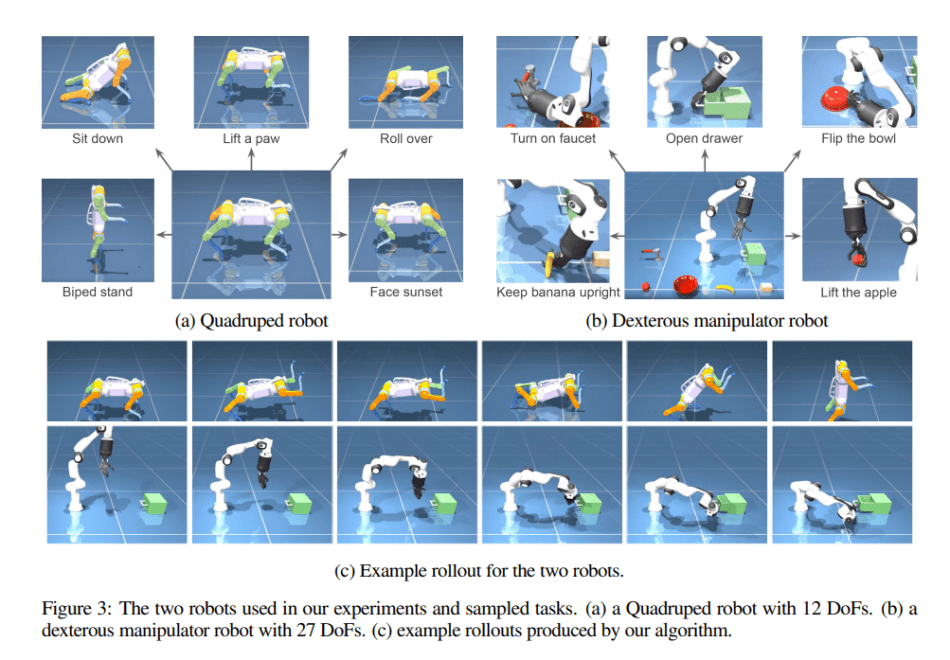


In their empirical study, the team performs their system on two simulated robotic systems: a quadruped robot, and a dexterous robot manipulator. The proposed system achieves significantly better performance in terms of reliability and its capability to solve diverse tasks then other baseline approaches that do not use reward as the interface.
The paper Language to Rewards for Robotic Skill Synthesis on arXiv.
Author: Hecate He | Editor: Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
This paradigm shift in leveraging reward functions to link language with robot actions seems like a game changer allowing for intuitive and accessible robot instruction without heavy data reliance.
Inground Pool Cleaning Services in Paradise NV
The blog post on https://writepapers.com/blog/history-research-paper-topics about history research paper topics is a fantastic resource for students and researchers seeking inspiration. It covers an extensive range of topics across different historical periods and themes, ensuring there is something for everyone. The topics are well-categorized, making it easy to navigate and find a subject that aligns with one’s interests and academic requirements.