
Following on the epoch-making performance of transformer architecture-based large language models, vision transformers (ViTs) have emerged as a powerful approach to image processing. Like their text-based predecessors, ViTs initially relied on multi-headed self-attention layers to capture features from input images, while more recent approaches have employed spectral layers to represent image patches in the frequency domain. Could ViTs benefit from an architecture that incorporates both methods?
In the new paper SpectFormer: Frequency and Attention Is What You Need in a Vision Transformer, a research team from Microsoft and the University of Bath proposes SpectFormer, a novel transformer architecture that combines spectral and multi-headed attention layers to better capture appropriate feature representations and improve ViT performance.

The team summarizes their main contributions as follows:
- We design SpectFormer by using initial spectral layers and multi-headed attention in deeper layers. We validate the choice of this architecture through thorough empirical validation.
- We show that SpectFormer gets reasonable performance when used in transfer learning mode (trained on ImageNet and tested on CIFAR datasets) on CIFAR-10, and CIFAR-100 datasets.
- Further, we show that SpectFormer obtains consistent performance in other tasks such as object detection and instance segmentation by evaluating its performance on the MS COCO dataset.

The team first explores how different combinations of spectral and multi-headed attention layers perform compared to exclusively attention or spectral models, concluding that equipping their proposed SpectFormer with initial spectral layers implemented with Fourier Transform followed by multi-headed attention layers achieves the most promising results.

The SpectFormer architecture has four main components: a patch embedding layer, a positional embedding layer, a transformer block comprising a series of spectral layers followed by attention layers, and a classification head. The SpectFormer pipeline first transforms image tokens to the Fourier domain (into spectral space), where a frequency-based analysis of the image information is performed and relevant features captured; then applies gating techniques via learnable weight parameters; and finally performs an inverse Fourier transform to return the signal from the spectral space to the physical space.

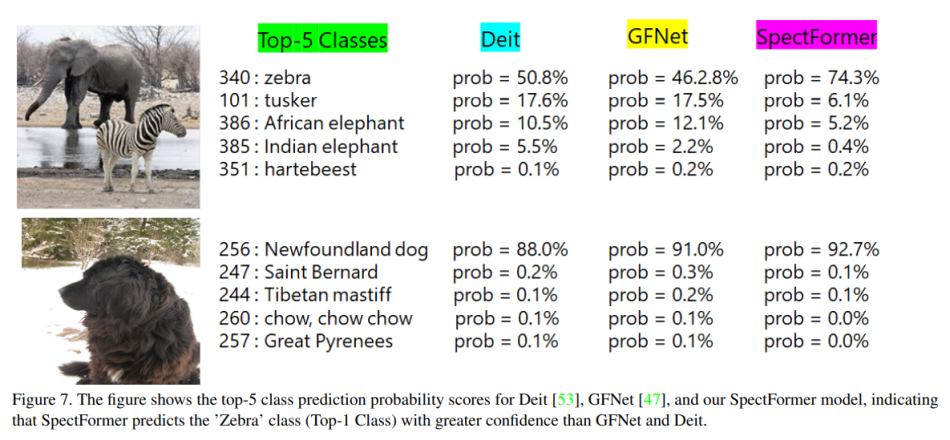
In their empirical study, the team compared SpectFormer with the multi-headed self-attention-based DeIT, the parallel architecture LiT, and the spectral-based GFNet ViTs on various object detection and image classification tasks. SpectFormer bettered all baselines in the experiments, achieving state-of-the-art top-1 accuracy (85.7%) on the ImageNet-1K dataset.
Code and additional information are available on the project’s webpage. The paper Spectformer: Frequency and Attention Is What You Need in a Vision Transformer is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Amazing post
Great article! The proposed SpectFormer architecture seems very promising. I’m curious about how it compares to other state-of-the-art models like Swin Transformer and ViT-L in terms of performance and computational efficiency. Do you think SpectFormer has the potential to become the new benchmark for vision transformers?
John
https://www.airiches.online/
I truly like how simple the reading is for me to do. I would want to learn how to get notified whenever a new post is created.
I really appreciate how easy it is for me to read. I’d want to find out how to be informed everytime a new post is made.
https://www.ghostwritingproficiency.com/
The advancements in vision transformers through Microsoft’s Spectformer are impressive, particularly how integrating frequency and attention mechanisms boosts performance. It’s exciting to see how these innovations can significantly enhance computer vision tasks. Here is an example https://geekydane.com/127-0-0-162893/
When I am very eager to decipher a mysterious word but can’t think of it, right now wordle hint can solve all difficult problems to help me find the mysterious word quickly.
vision transformers through Microsoft’s Spectformer are impressive, particularly how integrating frequency and attention mechanisms