
ChatGPT, which has been considered as part of “the generative-AI eruption” by Dereck Thompson in The Atlantic magazine’s “Breakthroughs of the Year” for 2022, has increased significant interest and competition in the space. Along with this trend, many tech giants around the world like Google, Miscrosoft are launching a ChatGPT-style service to join the competition with ChatGPT.
However, since OpenAI has not released the code for ChatGPT, how to effectively replicate ChatGPT has become a huge problem faced by everyone, and an open-source ChatGPT equivalent is in great demand.
The good news is that now Colossal-AI, as one of the hottest open-source solutions for large AI models, presents an open-source low-cost ChatGPT equivalent implementation process first, with highlights including:
● An open-source complete PyTorch-based ChatGPT equivalent implementation process, covering all 3 stages, which can help you build the ChatGPT-style service based on pre-trained models.
● We offer a mini demo training process for users to play around, which requires only 1.62GB of GPU memory and would possibly be achieved on a single consumer-grade GPU, with up to 10.3x growth in model capacity on one GPU.
● Compared to the original PyTorch, single-machine training process can be 7.73 times faster and single-GPU inference can be 1.42 times faster, which can be achieved in a single line of code.
● Regarding fine-tuning task, with one line of code, you are able to increase the capacity of the fine-tuning model by up to 3.7 times on a single GPU while keeping in a sufficiently high running speed.
● We provide multiple versions of a single-GPU scale, a multiple-GPUs scale on a single node, and an original 175-billion-parameter scale. We also support importing OPT, GPT-3, BLOOM and many other pre-trained large models from Hugging Face to your training process.
● Verification of convergence is in progress, and all users are invited to build up the community together.
GitHub Repo:https://github.com/hpcaitech/ColossalAI
ChatGPT – the industrial revolution led by AIGC
You may wonder, at the beginning of the new year, what is the most popular technology in AI? That should be ChatGPT.
It behaves like a hexagonal warrior that’s able to chat, write code, fix bugs, create forms, publish papers, do homework, translate, and even be a good competitor to Google search engine.
Since its release, ChatGPT has gained fame in all industries, catching the attention of millions of users in 5 days, hitting 100 million monthly active users 2 months after its launch. It has become the fastest growing application in history, far surpassing other well-known applications today, such as Twitter taking 5 years to hit 100M users , Meta (Facebook) taking 4 and a half years, TikTok taking 9 months and even 16 years were taken for mobile phones to reach 100M users.

Bill Gates praised ChatGPT as significant as the invention of the Internet, while Microsoft CEO Satya Nadella was more outspoken in saying, “AI will fundamentally change every software category.” As a major investor with tens of billions of dollars investment in OpenAI, Microsoft has quickly integrated ChatGPT into its own search engine Bing and Edge browser, with plans of adding to Teams, Office and other office suites. Its stock soared more than 80 billion dollars overnight.

Google Stock vs. Microsoft Stock after both AI Presentations
Worried about being beaten by ChatGPT at search, Google swiftly released the competitive product Bard. Yet its stock immediately evaporated by $100 billion because of the failure of its demo debut.
Overnight, the global tech giants are trying to be the first to launch their own ChatGPT-like service to dominate the market in this area.
Although ChatGPT has been released for several months, neither open-source pre-training weight nor a complete open source training process at low cost is available to the public. In fact, it’s difficult to realize the efficient replication of the whole process of ChatGPT-style service based on kinds of 100-billion-parameter models. Recently, a bunch of ChatGPT alternatives have been temporarily launched. But it is difficult to tell the difference because they are closed source.
Why is ChatGPT so magical? What are the difficulties in replicating it?
ChatGPT technical analysis
The important feature of ChatGPT’s amazing results is the introduction of human feedback reinforcement learning (RLHF) in the training process, to better capture human preferences.
The training process of ChatGPT is divided into three main stages.
- Sampling from the Prompt library, collecting its human responses, and using these data to fine-tune the pre-trained large language model.
- Sampling from the Prompt library, generating multiple responses using the large language model, manually ranking these responses, and training a reward model (RM) to fit human preference.
- Based on the supervised fine-tuning model in stage 1 and the reward model in stage 2, the large language model is further trained using reinforcement learning algorithms.
In stage 3, which is the core part of RLHF training, OpenAI adopts the Proximal Policy Optimization (PPO) algorithm in reinforcement learning to introduce the reward signal so that the language model generates content more in line with human preference.

The three stages of RLHF
The complexity of the ChatGPT model which comes from the introduction of reinforcement learning will bring more model calls. For example, using PPO algorithm based on Actor-Critic (AC) structure, we need to conduct forward inference and back-propagation of Actor and Critical models, as well as multiple forward inference of supervised fine-tuning model and reward model during training. Regarding the paper of InstructGPT, which’s the basis of ChatGPT, Actor and the monitoring fine-tuning model both use the GPT-3 series model with 175 billion parameters, while the critical and reward models use the GPT-3 series model with 6 billion parameters.
With such a large number of model parameters, to start the original ChatGPT training process requires thousands of GB of GPU memory, which is obviously far beyond the capacity of a single GPU, and the common data parallel technology is also not enough. However, even if tensor parallelism and pipelining parallelism are introduced to partition parameters, at least 64 80GB A100 GPU are still required as the hardware basis.What’s worse, pipelining is not suitable for AIGC’s generative tasks because of its complexity and efficiency due to its bubble and scheduling. Stage 3 involves the complex reinforcement learning and training process of four models, which further brings difficulties and challenges for ChatGPT’s code reproduction.
Low-cost replication of ChatGPT training process using Colossal-AI
Colossal-AI replicates the basic process of ChatGPT training in an open source way, including stage 1 pre-training, stage 2 reward model training, and stage 3 reinforcement learning training, the most complicated stage in the process.
Additionally, Colossal-AI greatly reduces the GPU memory overhead of ChatGPT training by using ZeRO, Gemini, LoRA, AutoChunk memory management, etc. It only requires half the hardware resources to start 175 billion parameter model training (from 64 cards to 32 cards), significantly reducing the cost of ChatGPT-style applications. With the same hardware resources mentioned above, Colossal-AI is able to train in less time, saving training costs and accelerating product iterations.
To allow more developers to run through ChatGPT training process, in addition to the original 175 billion parameter version, Colossal-AI also provides efficient single GPU, stand-alone 4/8-GPUs ChatGPT-like versions to reduce hardware restrictions.

On a single multi-GPUs server, even with the highest-end A100 80GB GPU, PyTorch can only launch ChatGPT based on small models like GPT-L (774M), due to the complexity and memory fragmentation of ChatGPT. Hence, multi-GPUs parallel scaling to 4 or 8 GPUs with PyTorch’s DistributedDataParallel (DDP) results in limited performance gains.
Colossal-AI not only has significant training and inference advantages in the speedup on single GPU, but can be further improved as parallelism scales up, up to 7.73 times faster for single server training and 1.42 times faster for single-GPU inference, and is able to continue to scale to large scale parallelism, significantly reducing the cost of ChatGPT replication.

To minimize training costs and ease of use, Colossal-AI also offers a ChatGPT training process that can be tried on a single GPU. Compared to PyTorch, which can only start up to 780 million parameter models on the $14,999 A100 80GB, Colossal-AI boosts the capacity of a single GPU by 10.3 times to 8 billion parameters. For ChatGPT training based on a small model with 120 million parameters, a minimum of 1.62GB of GPU memory is required, which can be satisfied by any single consumer-level GPU.
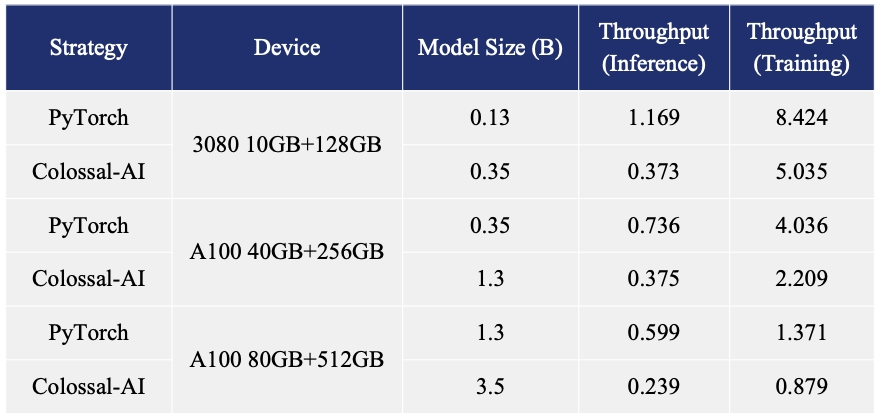
In addition, Colossal-AI is always trying to reduce the cost of fine-tuning tasks based on pre-trained large models. For example, the fine-tuing tasks regarding ChatGPT on OPT model, Colossal-AI is able to increase the capacity of the fine-tuning model on a single GPU by up to 3.7 times compared to PyTorch, while working at a sufficiently high speed.
One line of code to kickstart
Colossal-AI provides out-of-the-box ChatGPT training code. Users would find it easy to train the mainstream pre-trained models such as GPT, OPT and BLOOM from the Hugging Face community in ChatGPT-like method using Colossal-AI. In the case of GPT, for example, only one line of code is needed to specify the usage of Colossal-AI as a system strategy to kickstart.

Using the following commands, you can quickly start the training of the single-GPU scale, single machine multi-GPUs scale, the original 175-billion-parameter scale version, and have an evaluation on various performance indicators (including maximum GPU memory usage, throughput, and TFLOPS):

Underlying optimization
Core system: Colossal-AI
Replicating ChatGPT implementation process typically relies on Colossal-AI, a deep learning system for the big AI model era, which supports efficient and fast training and inference of large AI models based on PyTorch, and reduces the cost of large AI model deployment. Since open-source, Colossal-AI has ranked first on the GitHub Trending multiple times and has gained over 8,000 Stars. It has been chosen as the official tutorial for top AI and HPC conferences such as SC, AAAI, PPoPP and CVPR. Besides the optimizations above, Colossal-AI also provides various efficient solutions for massively parallelized and distributed training of big AI models, and has demonstrated superiority in cutting-edge models such as Stable Diffusion, OPT, and AlphaFold.

Comparison between Colossal-AI and current major open source projects in the same period
Colossal-AI is being led by Mr. James Demmel, a Distinguished Professor at the University of California, Berkeley, and Mr. You Yang, a Presidential Young Professor at the National University of Singapore. Its solutions have been successfully applied and acclaimed by some well-known tech giants in the fields of autonomous driving, cloud computing, retail, medicine, and chips. For example, Colossal-AI has successfully helped a Fortune-500 enterprise to develop a ChatGPT-like chatbot model with enhanced online searching capabilities.
Low-cost fine-tuning of LoRA
Colossal-AI supports efficient fine-tuning via the Low-Rank Adaptation (LoRA) method. The method assumes that large language models are over-parameterized and the change in parameters during fine-tuning can be represented as a low-rank matrix, which can be decomposed into the product of two smaller matrices:. With the parameters of large language models fixed, only the parameters of the decomposed matrices are being adjusted during fine-tuning; hence this method significantly reduces the amount of training parameters. To deploy for inference, the matrix product is added back to the original matrix, as, without affecting inference latency.

LoRA structure, we only train A and B.
Zero+Gemini to reduce memory redundancy
Colossal-AI uses Zero Redundancy Optimizer (ZeRO) to eliminate memory redundancy and enhance memory usage compared to traditional data parallelism, without compromising computational granularity and communication speed. Colossal-AI also puts forward chunk-based memory management, which further improves the performance of ZeRO. Chunk-based memory management stores consecutive sets of parameters in operational order in a continuous, evenly-partitioned memory space called chunks, for more efficient use of network bandwidth (between PCI-e and GPUs), reduced communication cost, and avoidance of potential memory fragmentation.

Chunk strategy
Furthermore, Colossal-AI’s heterogeneous memory manager, Gemini, reduces GPU memory footprint by offloading optimizer states to CPU, allowing for simultaneous use of GPU memory and CPU memory (including CPU DRAM or NVMe SSD memory) to train larger-scale models beyond the memory limit of a single GPU.

Increased Model Capacity with the Same Hardware by ZeRO + Gemini
Invitation to open-source contribution
Although having open-sourced the complete algorithmic and software designs to replicate ChatGPT implementation process, for such a giant AI model, it demands more data and computing resources to actually take effect and deploy. After all, training a GPT-3 with 175 billion parameters requires millions of dollars worth of computing power. Therefore, large pre-trained models have long been owned by only a few big-tech companies.
Good news is that the open source community has made a few successful trials. For example, the BLOOM model of 176 billion parameters with completely open-source codes, datasets, and model weights has involved more than 250 institutions from 60 countries around the world, and more than 1,000 developers, including employees of Meta, Google, and other major companies who participated personally. The open-source text-to-image generation model Stable Diffusion that went viral a few months ago, was also a joint effort by organizations such as Stability AI, EleutherAI, LAION, etc.
Referring to the above successful attempts, any and all developers and partners with computing powers, datasets, models are welcome to join and build an ecosystem with Colossal-AI, making efforts towards the era of big AI models from the starting point of replicating ChatGPT!
You may contact Colossal-AI or participate in the following ways:
- Posting an issue or submitting a PR on GitHub
- Join Colossal-AI WeChat or Slack group to communicate
- Check out and fill in the cooperation proposal
- Send your proposal to email contact@hpcaitech.com
GitHub Repo
https://github.com/hpcaitech/ColossalAI
Reference
https://www.hpc-ai.tech/blog/colossal-ai-chatgpt
(link used for cooperation proposal: https://www.hpc-ai.tech/partners)

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: Open Source Solution Replicates ChatGPT Training Process! Ready To Go With Only 1.6GB GPU Memory And Gives You 7.73 Times Faster Training! | GPT AI News