
The realistic, high-resolution human portraits generated by AI systems in recent years have wowed the Internet. While speech-driven portrait animation techniques designed to bring these faces to life have emerged as a new focus in the research community, existing approaches tend to struggle with issues such as pose variations, emotional control, and facial landmarks.
In the new paper SPACEx: Speech-driven Portrait Animation with Controllable Expression, an NVIDIA research team introduces SPACEx — a speech-driven portrait animation framework with controllable emotional expression. The novel approach generates high-resolution and expressive videos with controllable subject pose, emotion and expression intensity; and achieves state-of-the-art performance for speech-driven portrait image animation.

The team summarizes their main contributions as follows:
- We achieve state-of-the-art quality for speech-driven portrait image animation. SPACEx provides better quality in terms of FID and landmark distances compared to previous methods while also generating higher-resolution output videos.
- Our method can produce realistic head poses while also being able to transfer poses from another video. It also offers increased controllability by utilizing facial landmarks as an intermediate stage, allowing manipulations such as blinking, eye gaze control, etc.
- For the same set of inputs, our method allows for the manipulation of the emotion labels and their corresponding intensities in the output video.


SPACEx takes a speech clip and a single face image as input, and users can further condition the output video by adding an emotion label (happy, sad, surprise, fear). The framework decomposes tasks into three stages to improve interpretability and fine-grained controllability. In the first stage, Speech2Landmarks, the model predicts facial landmark motions in a normalized space based on the input image, speech and emotion label. In the second, Landmarks2Latents stage, the per-frame posed facial landmarks are translated into latent keypoints. Given the input image and per-frame posed facial landmarks, a pretrained image-based facial animation model, face-vid2vid, outputs an animated 512×512 resolution video in the final synthesis stage.

The team introduces a novel emotion conditioning technique that uses feature-wise linear modulation layers (FiLM, Perez et al., 2017) to enable controllable emotional expression and intensities in the generated video. In the Speech2Landmarks network, FiLM modulates the audio features and the initial landmark input. In the Landmarks2Latents network, FiLM is applied on the audio, landmarks, and the initial latent keypoint input.
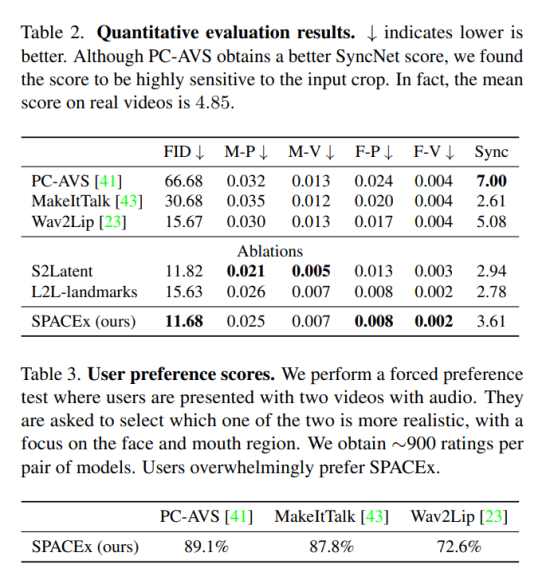
In their empirical study, the team compared SPACEx to Wav2Lip, MakeItTalk, and Talking Face-PC-AVS (PC-AVS) baselines on various talking-head video generation tasks. In the evaluations, SPACEx achieved the best performance in terms of FID and landmark distances while generating higher resolution output videos with superior facial expression controllability.
The team believes SPACEx’s capabilities could open promising new avenues in video conferencing, gaming, and media synthesis.
Sample videos and additional information are available on the project website: https://deepimagination.cc/SPACEx/. The paper SPACEx: Speech-driven Portrait Animation with Controllable Expression is on arXiv.
Author: Hecate He | Editor: Michael Sarazen, Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
great blog
To improve interpretability and fine-grained controllability, the framework divides tasks into three stages.
The forum content that you shared with me has provided me with a significant amount of knowledge that is useful. I really hope you’ll start posting updates more frequently.
Afternoon. In my opinion online gaming helped me a lot, especially cs go. then the constant communication with strangers, albeit in voice chat, helped me get rid of the feeling of loneliness. In addition, I found a new hobby. I actively collect skins for awp or sometimes buy them like mac 10 neon rider. It really takes my mind off sad thoughts.
Now there are many games, but at the same time, I often see low-quality 2D and 3D animation. In order to avoid such problems that really worsen the overall experience of the game, I recommend contacting experienced outsourced developers https://ilogos.biz/2d-game-art-outsoursing/ . This is the best way to get a quality result.
Visit ttps://modfunda.com/ today and revolutionize your app and gaming experience with our extensive range of modded APKs. Unleash the power of mods and take your digital journey to the next level!
Check out ‘
9animes‘ for an unbeatable anime experience. Their vast collection and easy-to-navigate interface will not disappoint you. Highly recommended!
Bokyna sandals offer comfort, style, and durability for women in all activities. With ergonomic designs and quality materials, they provide confidence and comfort for any adventure. Explore our collection for the perfect blend of fashion and function.
I am Content Marketer at The Nordic Socks. At The Nordic Socks, you can get comfy socks for women and men. Our Scandinavian socks are soft, comfortable, and available in a range of colors and styles.For more information visit our Website The Nordic Socks. https://rollbol.com/blogs/1876783/How-Do-Classic-Socks-Fit-into-Today-s-Fashion-Trends
Passionate about simplifying workforce management. Creator of , a powerful timesheet software that automates Modern Award compliance, tracks work hours, and enhances payroll accuracy. Committed to helping businesses thrive through efficient, transparent, and compliant processes.
Lets Neon offers custom neon signs and lights, allowing customers to personalize designs for homes, businesses, and special events. They provide high-quality, energy-efficient LED neon lights in various styles and sizes. Their products are ideal for interior decor, weddings, parties, and branding needs. Lets Neon focuses on creating vibrant, durable signs with fast shipping and customization options. https://letsneon.com/
Lets Neon offers custom neon signs and lights, allowing customers to personalize designs for homes, businesses, and special events. They provide high-quality, energy-efficient LED neon lights in various styles and sizes. Their products are ideal for interior decor, weddings, parties, and branding needs. Lets Neon focuses on creating vibrant, durable signs with fast shipping and customization options.
Blush Mark brings you fashion that truly feels like you, combining modern trends with everyday comfort and effortless style. From casual essentials to statement pieces, every collection is designed to help you express your personality with confidence. Discover clothing that fits your lifestyle, celebrates your individuality, and keeps you looking your best every day.
REV Tonneau Covers deliver premium hard folding and rolling truck bed protection, keeping your cargo secure from rain, dust, and theft without compromising style. Built with durable materials and precision engineering, they provide long-lasting performance and quick, hassle-free access to your truck bed.
Tonka Trucks have been delivering rugged, durable toy vehicles since 1947, earning the trusted reputation of being “Tonka Tough.” Built to withstand years of imaginative play, these iconic trucks feature realistic designs and sturdy construction for kids of all ages.