
While self-supervised learning (SSL) has achieved impressive results in recent years thanks to complex data augmentation techniques and lengthy training schedules, these approaches also lead to extremely high computation costs. Given a fixed FLOPS budget, is it possible to identify the best datasets, models, and self-supervised training strategies for obtaining high accuracy on visual tasks?
In the new paper Where Should I Spend My FLOPS? Efficiency Evaluations of Visual Pre-training Methods, a research team from DeepMind and the NYU Center for Neural Systems introduces evaluation approaches designed to measure the computational efficiency of various visual pretraining strategies across multiple datasets and model sizes and aid in the selection of optimal methods, datasets and models for pretraining visual tasks on a fixed FLOP budget.

Previous studies on SSL have mainly focused on improving performance with little regard for the associated computational costs. This work takes the first steps toward identifying computationally optimal pretraining methods, datasets and models.
The team analyzes four common self-supervised methods (BYOL, SimCLR, DINO, and MAE) and two supervised methods (CLIP and standard softmax classification). The methods’ per gradient-step FLOP costs are computed and used for comparisons across three axes: pretraining method, model size, and dataset. Downstream task performance is measured by finetuning the pretrained encoders on semantic segmentation tasks on the ADE20K dataset.
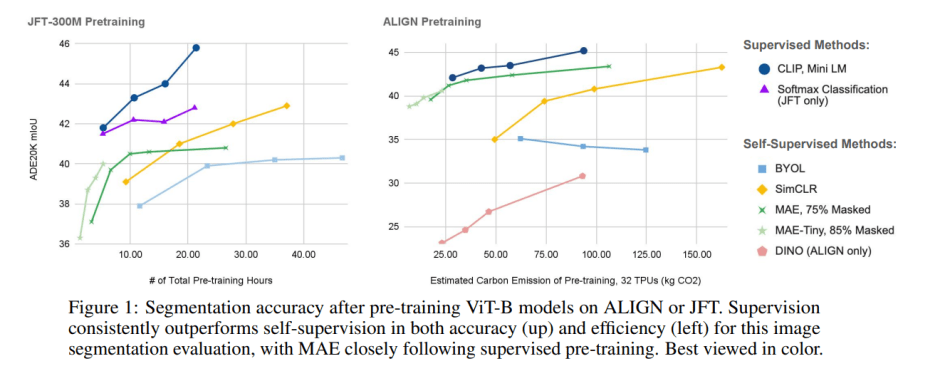


Based on the evaluations, the team concludes that: 1) Self-supervised methods are generally less FLOP efficient and supervised representations dominate the efficiency Pareto-front; 2) For most methods, the small and large model curves intersect, indicating the point at which it is better to switch to larger model sizes for a given FLOP budget; 3) Dataset quality and curation level significantly affect model accuracy.
The team sees their work as a first step towards more rigorously measuring the computational efficiency of contemporary supervised and self-supervised pretraining approaches in terms of pretraining method, dataset and model size. They hope their results will spark future research into visual SSL methods that learn more effectively and scalably on uncurated data.
The paper Where Should I Spend My FLOPS? Efficiency Evaluations of Visual Pre-training Methods is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
So many people underestimate the infras and codes available in Google. You can basically jump in and train LLM in like a week in the internship.