
Writing a few paragraphs is a relatively simple task for most humans, but even experienced novelists often run into problems when trying to develop their second chapter. A similar issue hinders today’s large-scaled pretrained language models such as GPT-2, which have achieved astounding performance in short text generation, but whose longer texts tend to devolve into incoherence. This failure to properly evolve documents from beginning to end can be attributed to such models’ inability to plan ahead or represent long-range dynamics.
To address these issues, a Stanford University research team has proposed Time Control (TC), a language model that implicitly plans via a latent stochastic process and aims to generate texts consistent with this latent plan. The novel approach improves performance on long text generation, with human evaluators scoring the outputs 28.6 percent higher than those of baseline methods.

The team summarizes their main contributions as:
- We derive Time Control, a language model which explicitly models latent structure with Brownian bridge dynamics learned using a novel contrastive objective.
- Across a range of text domains, we show that Time Control generates more or equally coherent text on tasks including text infilling and forced long text generation, compared to task-specific methods.
- We validate that our latent representations capture text dynamics competitively by evaluating discourse coherence with human experiments.
- We ablate our method to understand the importance of the contrastive objective, enforcing Brownian bridge dynamics, and explicitly modelling latent dynamics.

The proposed TC method learns a latent space with smooth temporal dynamics for modelling and generating coherent text. Specifically, the team derives a novel contrastive objective for learning a latent space with Brownian bridge dynamics, then uses this latent space to generate text that retains local coherence while also demonstrating improved global coherence.
The TC text generation pipeline first plans a latent trajectory via the Brownian bridge process pinned at a start and end point, then conditionally generates sentences following this latent plan.
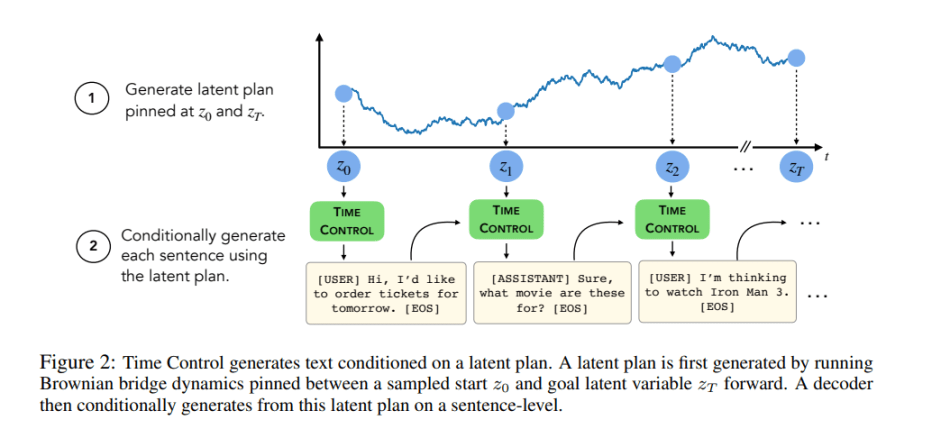
The team’s empirical study explored four questions: 1) Can Time Control model local text dynamics? 2) Can Time Control generate locally coherent text? 3) Can Time Control model global text dynamics? and 4) Can Time Control generate long coherent documents?
They compared TC to domain-specific methods and fine-tuning on GPT-2 across a variety of text domains on three tasks: discourse coherence, text-infilling, document structure mimicking and long text generation. Datasets employed in the evaluations included Wikisection, TM-2, TicketTalk and Recipe NLG.




In the tests, TC improved performance on text infilling and discourse coherence tasks and preserved text structure for long text generation both in terms of ordering (up to +40 percent better) and text length consistency (up to +17 percent better), demonstrating the proposed method’s ability to generate more locally and globally coherent texts.
The team believes TC could also be extended to other domains with sequential data, like videos or audio, or to handle arbitrary bridge processes without known fixed start and end points.
The accompanying code can be found on the project’s GitHub. The paper Language Modeling via Stochastic Processes is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
0 comments on “Stanford U’s Language Model Leverages Stochastic Processes to Improve Efficiency and Coherence in Long Text Generation”