
Deep neural networks (DNNs) are a prevalent architecture in the machine learning community due to their impressive capability to model complex real-life problems. Recent research (Kaplan et al., 2020; Allen-Zhu et al., 2019a) however has suggested that such networks tend to be vastly overparameterized, such that the development of modern DNNs requires substantial and potentially wasteful increases in model size and compute burden.
In the new paper DataMUX: Data Multiplexing for Neural Networks, a Princeton University research team explores the question: “If networks contain greater processing capacity than necessary, could it be possible for them to model a function over multiple inputs simultaneously, similar to how radio channels share bandwidth to carry multiple information streams at once?” To address this question and improve DNNs’ efficiency and throughput, the team proposes Data Multiplexing (DataMUX), a novel technique that enables neural networks to process multiple inputs simultaneously and generate accurate predictions, increasing model throughput with minimal additional memory requirements.

The proposed DataMUX is designed to simultaneously and effectively compress a mixture of inputs (up to 40) over a shared neural network with minimal overhead during inference. It has three components: 1) a multiplexer module that combines multiple input instances into a superposed representation, 2) a neural network backbone, and 3) a demultiplexing method that disentangles the processed representations for individual prediction.

The DataMUX multiplexing layer applies a fixed linear transformation to each input before integrating them as a single “mixed” representation that is fed into the base network, where it is processed into a “mixed” vector representation. The demultiplexing layer then converts this vector representation back into a set of vector representations corresponding to each original input, which are then used to generate the final outputs for each instance. Because the multiplexing and demultiplexing layers are end-to-end differentiable, it is possible to train the entire model jointly through standard gradient descent methods.
The team evaluated the performance of the proposed DataMUX on transformer, MLP, and CNN architectures applied to six tasks in sentence classification, named entity recognition and image classification.
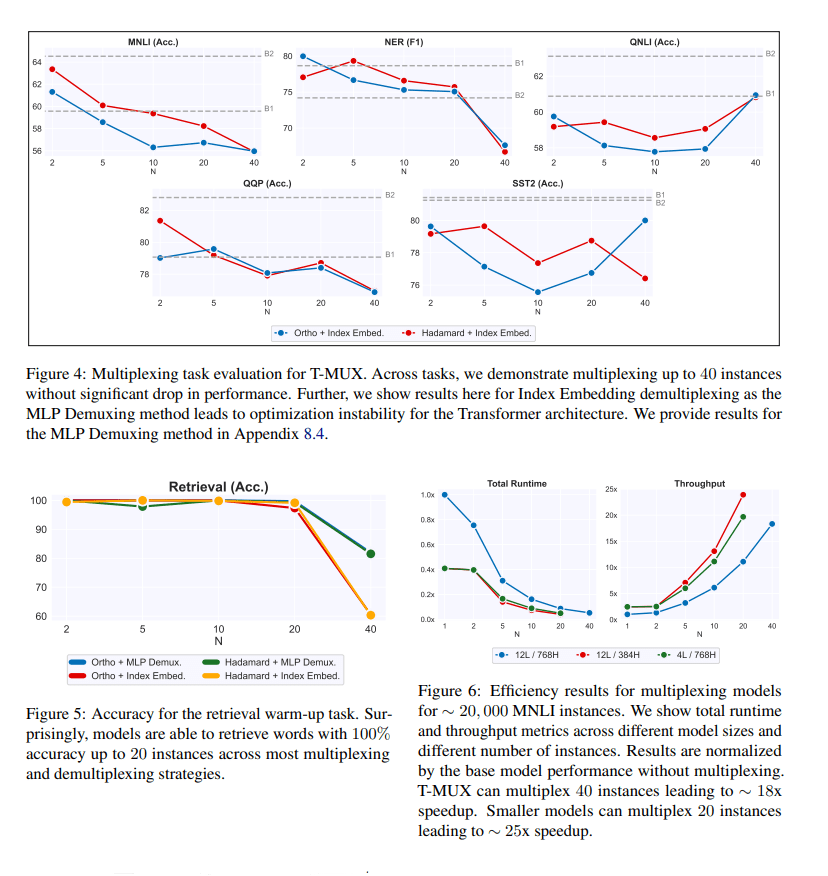
The experimental results show that multiplexing leads to minimal performance drops even for large numbers of instances, perfect multiplexing (near 100 percent) can be achieved on the retrieval warm-up task for large numbers of instances, and throughput can be increased multi-fold. The team’s analysis of the results concludes that the number of attention heads seems invariant to multiplexing, DataMUX can also boost throughput on smaller transformers, and performance varies more across different indices as the number of instances increases.
Overall, the study demonstrates that neural networks can be trained to predict on multiple input instances simultaneously using data multiplexing techniques that incur minimal additional compute overhead or learned parameters; and that the minimal performance degradations of the proposed DataMUX setting for multiplex training and inference are offset by dramatically increased system throughput.
The researchers suggest future research in this area could involve large-scale pretraining, multi-modal processing, multilingual models, different mechanisms of multiplexing and demultiplexing, and a more rigorous exploration of the architectural, data and training conditions that enable effective data multiplexing.
The paper DataMUX: Data Multiplexing for Neural Networks is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
0 comments on “Princeton U’s DataMUX Enables DNNs to Simultaneously and Accurately Process up to 40 Input Instances With Limited Computational Overhead”