
Stunning, high-resolution AI-generated images have wowed the Internet in recent years, products of deep image synthesis techniques largely enabled by generative adversarial networks (GANs). Today’s leading GAN models however can suffer from vexing issues such as training instability and mode collapse, which result in a lack of sample diversity. These issues, along with the increasingly powerful performance of transformer architectures and large language models like Open AI’s GPT, have inspired the research and development of generative transformer models for image synthesis.
In the new paper MaskGIT: Masked Generative Image Transformer, a Google Research team introduces a novel image synthesis paradigm that uses a bidirectional transformer decoder. Their proposed MaskGIT (Masked Generative Image Transformer) model significantly outperforms state-of-the-art transformer models on the ImageNet dataset and accelerates autoregressive decoding by up to 64x.


Generative transformer models are the current state-of-the-art approach for image synthesis. Such models aim at modelling an image as a sequence and leveraging existing autoregressive models to generate the image. The Google team regards this strategy as neither optimal nor efficient, as unlike text inputs (where transformer architectures excel), images are not sequential, and treating images as a flat sequence means the autoregressive sequence length grows quadratically, resulting in very high computation burdens.

The team therefore set out to design a new image synthesis paradigm utilizing parallel decoding and bi-directional generation to address the abovementioned issues. Their proposed MaskGIT follows a two-stage recipe: In the first stage (tokenization), MaskGIT attempts to compress images into a discrete latent space; In the second stage, the model predicts the latent priors of the visual tokens using deep autoregressive models, then uses the decoder from the first stage to map the token sequences into image pixels.
The main goal of this work was to improve the second stage. To this end, the team proposed learning a bidirectional transformer via masked visual token modelling (MVTM), a mask prediction strategy similar to that employed in Google’s BERT language model. Unlike with autoregressive modelling, the conditional dependency in MVTM has two directions, which enables its image generation to utilize richer contexts by attending to all tokens in the image.
At each iteration, MaskGIT predicts all tokens simultaneously in parallel but only keeps those in which it has the most confidence; the remaining tokens are then masked out to be re-predicted in the next iteration. This approach enables MaskGIT to achieve decoding speeds that are an order-of-magnitude faster than autoregressive decoding. Moreover, MaskGIT’s adopted bidirectional self-attention mechanism enables the model to generate new tokens from the generated tokens in all directions. The researchers say this mask scheduling (i.e. a fraction of the image masked at each iteration) significantly affects image generation quality.
The team evaluated MaskGIT on image generation tasks on the ImageNet dataset, comparing it against benchmark models DCTransformer, BigGAN-deep, Improved DDPM, ADM, VQVAE-2 and VQGAN.
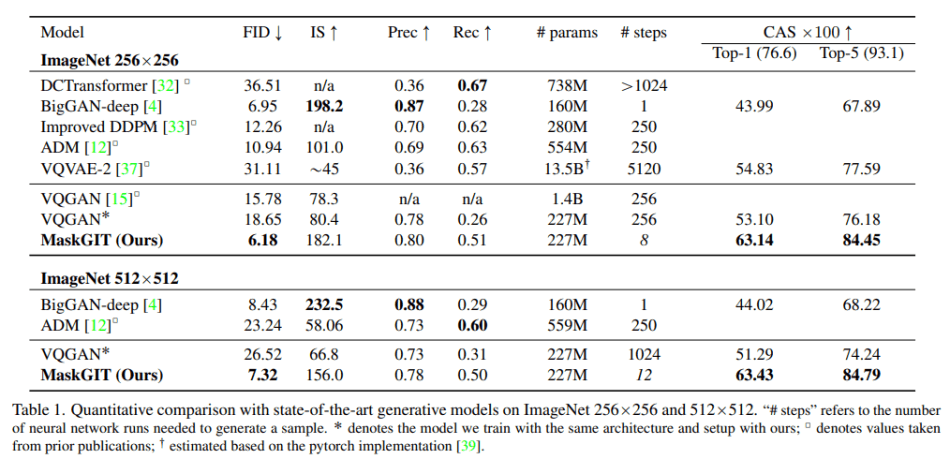


In the experiments, MaskGIT achieved better coverage (recall) compared to BigGAN and better sample quality (precision) compared to likelihood-based models. MaskGIT’s samples were also more diverse than BigGAN’s, with more varied lighting, poses, scales and context. MaskGIT also improved on diversity compared to VQGAN, while being up to 64x faster.
Overall, the study shows that MaskGIT is significantly faster and capable of generating higher quality samples than state-of-the-art autoregressive transformers. The team notes that their model is readily extendable to various image manipulation tasks and identifies applying MaskGIT to other synthesis tasks as a promising direction for future work.
The paper MaskGIT: Masked Generative Image Transformer is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
0 comments on “Google’s MaskGIT Outperforms SOTA Transformer Models on Conditional Image Generation and Accelerates Autoregressive Decoding by up to 64x”