
From the 1997 victory of IBM’s Deep Blue over chess master Garry Kasparov to DeepMind’s AlphaGo 2016 win against Go champion Lee Sedol and AlphaStar’s 2019 drubbing of top human players in StarCraft, games have served as useful benchmarks and produced headline-grabbing milestones in the development of artificial intelligence systems. Although today’s AI agents have surpassed human performance across a wide range of games, their training and performance tend to be restricted to a single game.
In a new paper, DeepMind researchers introduce Player of Games (PoG), a general-purpose algorithm that applies self-play learning, search, and game-theoretic reasoning to both perfect information and imperfect information games, taking an important step toward the realization of truly general algorithms for arbitrary environments.

An important ingredient for intelligent game-playing agents is tree search techniques. Foremost among these is Monte Carlo tree search (MCTS), proposed by Kocsis and Szepesvári in 2006, which drove AI agents’ early successes in Go and has advanced their performance on other perfect information games.
In imperfect information games such as poker it is possible to exploit any knowledge of hidden information to choose an effective counter-strategy, and so players should act in a way that does not reveal their own private information. This game-theoretic reasoning emerges by computing minimax-optimal strategies and has played a central role in the development of powerful poker AI agents over the last 20 years.

In search-based decision-making, where each state could depend on past gameplay, time limits, and samples of stochastic events, new solutions are computed at decision time. Counterfactual regret minimization (CFR) algorithms can be used to compute policies via self-play, with each iteration traversing the entire game tree and recursively computing values for information states from other values at subgames deeper in the tree. Safe re-solving meanwhile is a technique that generates subgame policies from only summary information of a previous solution, and continual re-solving uses repeated safe re-solving applications to adapt to imperfect information games. The proposed PoG employs a more general re-solving method to make it suitable for a broader class of games.
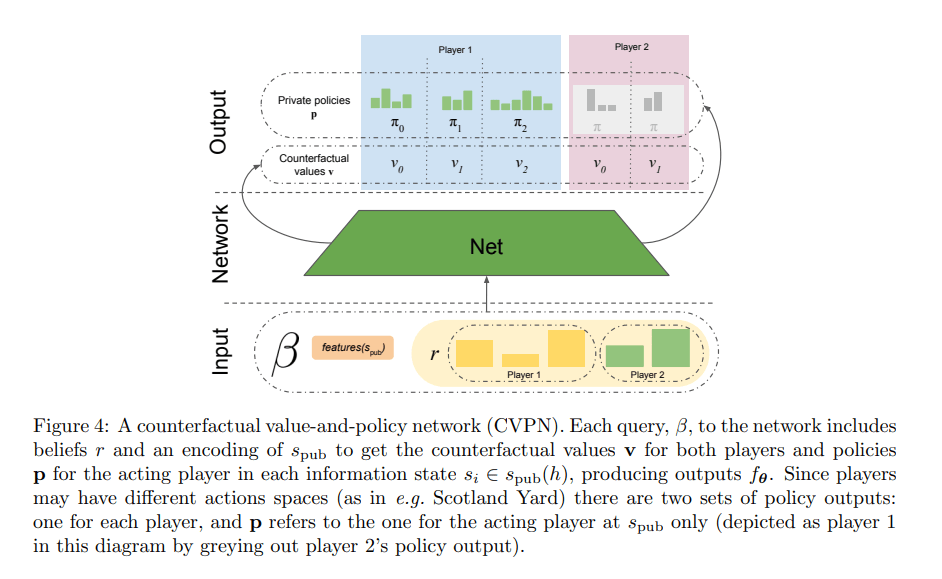
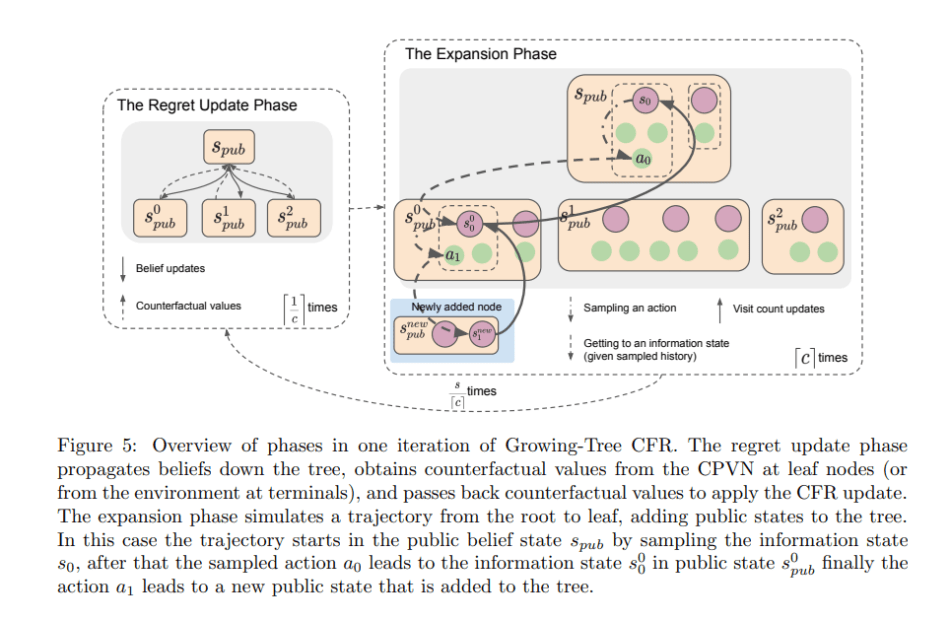
The DeepMind team leveraged these concepts to create PoG, which includes a counterfactual value-and-policy network (CVPN), search via growing-tree CFR (comprising a regret update phase and expansion phase), and data generation via sound self-play.
The PoG algorithm learns via this sound self-play, employing the growing-tree CFR search equipped with the counterfactual value-and-policy network to generate a policy which is then used to sample possible actions. Notably, the self-play data generation and training happen in parallel: actors generate the self-play data while trainers learn new networks and periodically update the actors.



The team evaluated PoG on chess, Go, heads-up no-limit Texas hold ’em poker, and Scotland Yard, a map-based board game with a detective theme. Although PoG could not match the performance of top specialized gameplay algorithms on perfect information games, it prevailed over the Stockfish chess engine using four threads and one second of search time; and achieved top human amateur level performance in Go. In the imperfect information games, PoG beat Slumbot, the best openly available poker agent; and bettered the state-of-the-art PimBot on Scotland Yard with 10M search simulations (55 percent win rate).
The results show that the PoG unified algorithm can be effectively applied to both perfect and imperfect information games and is the first algorithm to demonstrate strong performance across a wide range of challenge domains while using only minimal domain knowledge.
The paper Player of Games is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: r/artificial - [R] DeepMind’s PoG Excels in Perfect and Imperfect Information Games, Advancing Research on General Algorithms for Arbitrary Environments - Cyber Bharat