
Whether the search is for action films, e-bicycles or the best route to a coffee shop, data-based recommender systems will sift through the countless possibilities and guide users toward solutions most likely to fit their needs and preferences. Recommender systems can leverage the experiences of knowledgeable experts along with real-time information that users cannot access easily or quickly. Although they have been widely deployed and are proven business-boosters, recommenders are far from perfect, and generally lack the ability to predict users’ payoffs associated with specific alternatives.
In the paper Deviation-Based Learning, a research team from New York University and the University of British Columbia proposes deviation-based learning, a novel approach for training recommender systems that learns user knowledge by observing whether they follow or deviate from the provided recommendations.

The study trains a recommender system based on past recommendation data and users’ final decisions, aiming to evaluate models by observing expert users’ deviations. The idea is that if a model is well-trained, expert users will deviate less from its recommendations; while if the deviations are large, the recommender will recognize it had misestimated the underlying state. Also, if a user follows a particular recommendation even though the prediction confidence is low, the level of confidence in such predictions can be improved accordingly, leading to more precise and useful systems.
To consider user-payoff predictions, existing recommender approaches have adopted rating-based learning, which substitutes user-submitted ratings for payoffs. The paper notes however that user-generated ratings are often informed by various biases, and so provide only limited informative signals regarding users’ true payoffs.
The team also argues that rating-based learning can be powerless for example in detecting issues and hazards in car navigation and route-planning, as detailed ratings and reviews are often unavailable, and if the navigation app waits until it observes low payoffs, delays, incidents or accidents can occur. Moreover, such problems cannot be effectively solved by manually inputting hazard information, as it is difficult to know and list all relevant hazard conditions in advance.
The proposed deviation-based learning approach addresses such navigation problems by taking advantage of the knowledge of local (expert) drivers. Upon observing local drivers’ deviations from a suggested route, the recommender can update its knowledge about the static map; while if local drivers choose a route the system had considered hazardous, the recommender can also leverage this information to update its knowledge about that road.
The team provides simulation results for the proposed deviation-based learning approach, including plots of cumulative regret that analyze how regret and width of the confidence region evolve over time; plots that show how the width of the confidence region is updated; and the accuracy gain from each recommendation with regard to binary and ternary recommendations.

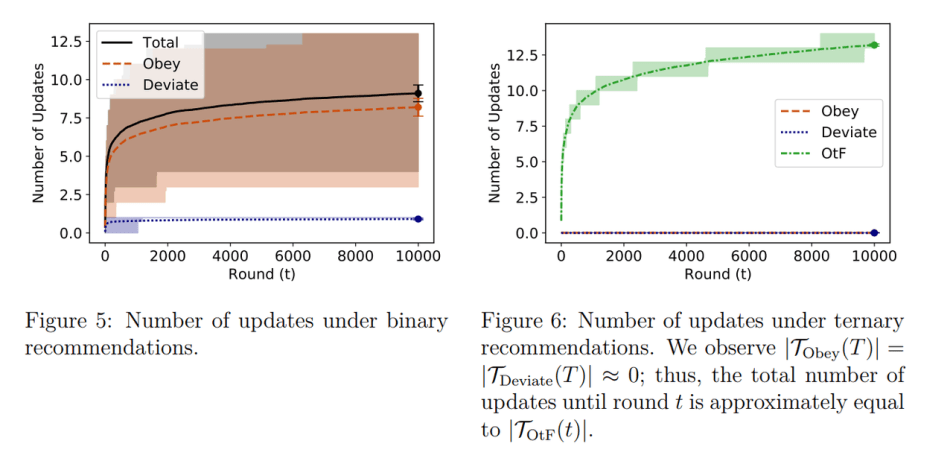

The team concludes that acquiring information from deviation-based learning is most effective when payoffs are unobservable, there are many knowledgeable experts, and the recommender can easily identify the set of experts. Overall, the proposed approach aims to provide information advantages in general environments that can be used to improve the accuracy of recommender systems and ultimately help users make better decisions.
The paper Deviation-Based Learning is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: r/artificial - [R] NYU & UBC Propose Deviation-Based Learning to Advance Recommender System Training - Cyber Bharat
very goooooooooooooooood