
Sequence to sequence modelling (seq2seq) with neural networks has become the de facto standard for sequence prediction tasks such as those found in language modelling and machine translation. The basic idea is to use an encoder to transform the input sequence into a context vector; then use a decoder to extract an output sequence that predicts the next value from that vector.
Despite their power and impressive achievements, seq2seq models are often sample-inefficient. Also, due to their relatively weak inductive biases, these models can fail spectacularly on benchmarks designed to test for compositional generalization.
The new MIT CSAIL paper Sequence-to-Sequence Learning with Latent Neural Grammars proposes an alternative, hierarchical approach to seq2seq learning with quasi-synchronous grammars, developing a neural parameterization of the grammar which enables parameter sharing over the combinatorial space of derivation rules without requiring manual feature engineering.

The paper identifies three ways in which the proposed approach differs from previous work in this area:
- We model the distribution over the target sequence with a quasi-synchronous grammar which assumes a hierarchical generative process whereby each node in the target tree is transduced by nodes in the source tree.
- In contrast to the existing line of work on incorporating (often observed) tree structures into sequence modelling with neural networks, we treat the source and target trees as fully latent and induce them during training.
- Whereas previous work on synchronous grammars typically utilized log-linear models over handcrafted/pipelined features, we make use of neural features to parameterize the grammar’s rule probabilities, which enables efficient sharing of parameters over the combinatorial space of derivation rules without the need for any smoothing or feature engineering.
Typically, quasi-synchronous grammars define a monolingual grammar over target strings conditioned on a source tree, where the grammar’s ruleset depends dynamically on the source tree. This work instead uses probabilistic quasi-synchronous context-free grammars (QCFG), which transduce the output tree by aligning each target tree node to a subset of source tree nodes, making it suitable for tasks where syntactic divergences are common.
Also, this grammar does not need to capture hierarchical structures implicitly within a neural network’s hidden layers; rather it can explicitly model the hierarchical structure on both the source and target side, resulting in a more interpretable generation process.
As each source tree node often occurs a few times in the training corpus, parameter sharing is required. While previous work on QCFGs involved intensive manual feature engineering to share parameters across rules, this approach instead employs a neural parameterization to enable efficient sharing of parameters over the combinatorial space of derivation rules.
For evaluation purposes, the proposed approach was applied to various seq2seq learning tasks, including a SCAN language navigation task designed to test for compositional generalization, style transfer on the English Penn Treebank, and small-scale English-French machine translation.
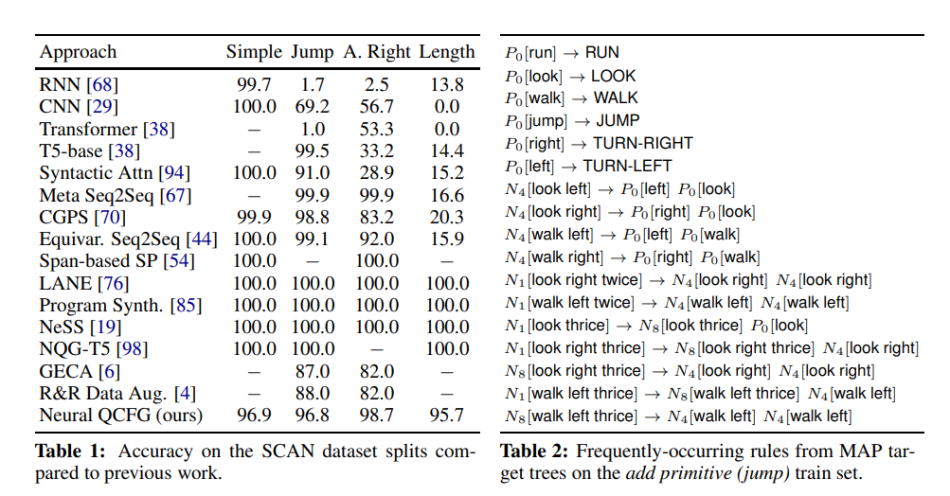

In the experiments, the proposed approach achieved decent performance on niche datasets such as SCAN and StylePTB, but woefully underperformed compared to a well-tuned transformer on machine translation tasks.
Overall, the study shows that the formalism of quasi-synchronous grammars can provide a flexible tool for imbuing inductive biases, operationalize constraints, and interface with models. The paper proposes future work in this area could involve revisiting richer grammatical formalisms with contemporary parameterizations, conditioning on images/audio for grounded grammar induction, adaption to programs and graphs, and investigating the integration of grammars and symbolic models with pretrained language models to solve practical tasks.
The paper Sequence-to-Sequence Learning with Latent Neural Grammars is on arXiv.
Author: Hecate He | Editor: Michael Sarazen, Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: r/artificial - [R] MIT Presents New Approach for Sequence-to-Sequence Learning with Latent Neural Grammars - Cyber Bharat
Pingback: MIT Presents New Approach for Sequence-to-Sequence Learning with Latent Neural Grammars | Synced – Notes de Francis
goooooooooood