
As deep neural networks (DNNs) are now increasingly deployed in real-life applications, their vulnerability to adversarial example attacks has raised concerns from machine learning practitioners, especially in the case of safety- and security-sensitive areas such as autonomous driving.
Transfer-based attacks are a black-box attack approach that offer greater practicality and flexibility over other attack methods, and have thus become a main research interest in this field. However, adversarial examples crafted by such traditional attacking methods often exhibit weak transferability, as they tend to indiscriminately distort features to degrade prediction accuracy in a source model without any awareness of the important intrinsic features of the objects they are distorting.
To alleviate this issue, a new paper from researchers at Zhejiang University, Wuhan University and Adobe Research proposes Feature Importance-Aware Attacks (FIA) that drastically improve the transferability of adversarial examples, outperforming current state-of-the-art transferable attack methods.

The researchers summarize their main contributions as:
- We propose Feature Importance-Aware Attacks (FIA) that enhance the transferability of adversarial examples by disrupting the critical object-aware features that dominate the decision of different models.
- We analyze the rationale behind the relatively low transferability of existing works, i.e., overfitting to model-specific “noisy” features, against which we introduce an aggregate gradient to guide the generation of more transferable adversarial examples.
- Extensive experiments on diverse classification models demonstrate the superior transferability of adversarial examples generated by the proposed FIA as compared to state-of-the-art transferable attacking methods.

Most DNN-based classifiers extract semantic features to effectively boost classification accuracy, as these semantic features are object-aware discriminative. Thus, if adversarial examples can disrupt object-aware features that dominate the decisions of all models, transferability will be improved. Current DNN models also extract exclusive features to better fit themselves to the data domain, and without awareness of these exclusive features, existing adversarial attack methods tend to craft adversarial examples by indiscriminately distorting features against a source model, resulting in model-specific local optimums that significantly degrade transferability.

Avoiding these local optimums is therefore key to improving transferability. Motivated by this premise, the proposed FIA obtains feature importance by introducing an aggregate gradient that averages gradients with respect to feature maps of the source model, enabling it to effectively avoid local optimums while representing transferable feature importance.

The paper highlights the advantage of feature importance awareness over traditional related feature-based attacks. From objective functions, related feature-based attack methods simply optimize the feature distortion between the original images and the adversarial images without any constraints. The FIA method differs in this regard by providing intrinsic feature importance via its aggregate gradient, enabling it to achieve better transferability in its adversarial examples.
To evaluate the proposed FIA’s effectiveness, the team compared it with state-of-the-art attack methods such as MIM, DIM, TIM, PIM, FDA etc. The experiments were conducted on an ImageNet-compatible dataset, and the success rate of the various attack methods was reported.
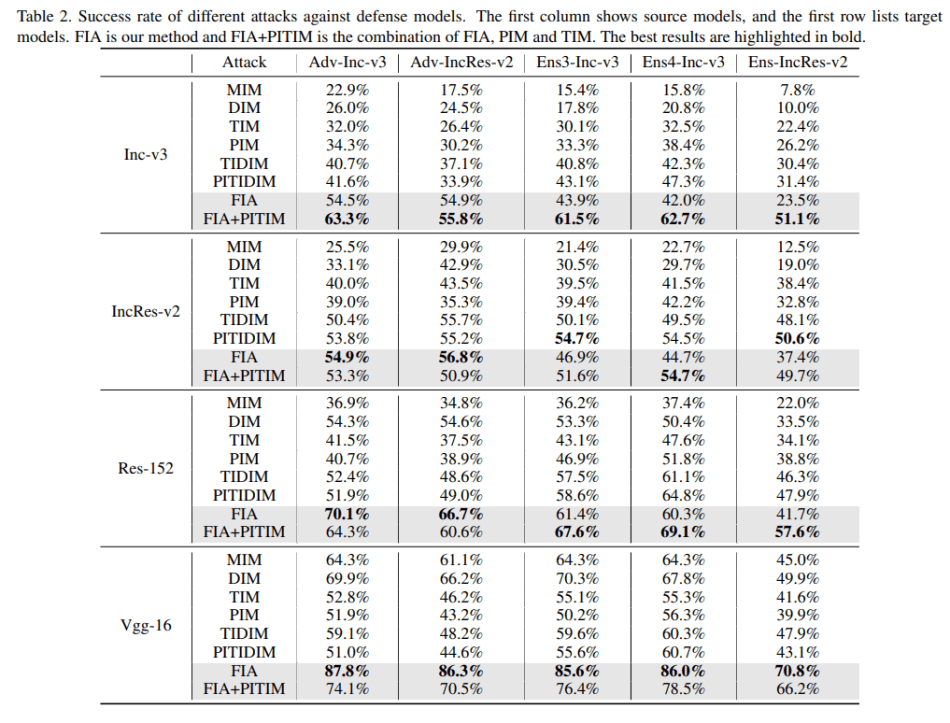
When compared to state-of-the-art transferable attacks, FIA improved the success rate by 8.4 percent in normally trained models and 11.7 percent in dedicated defence models.
The results demonstrate the superior transferability of adversarial examples generated by the proposed FIA, which the team hopes can serve as a benchmark for evaluating the robustness of various models.
The FIA code will be released on the project GitHub. The paper Feature Importance-Aware Transferable Adversarial Attacks is on arXiv.
Author: Hecate He | Editor: Michael Sarazen, Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: r/artificial - Novel Feature Importance-Aware Transferable Adversarial Attacks Dramatically Improve Transferability - Cyber Bharat
Pingback: [R] Novel Feature Importance-Aware Transferable Adversarial Attacks Dramatically Improve Transferability : MachineLearning - TechFlx
goooooooooood