
First-order methods for solving quadratic programs (QPs) are widely used for rapid, multiple-problem solving and embedded optimal control in large-scale machine learning. The problem is, these approaches typically require thousands of iterations, which makes them unsuitable for real-time control applications that have tight latency constraints.
To address this issue, a research team from the University of California, Princeton University and ETH Zurich has proposed RLQP, an accelerated QP solver based on operator-splitting QP (OSQP) that uses deep reinforcement learning (RL) to compute a policy that adapts the internal parameters of a first-order quadratic program (QP) solver to speed up the solver’s convergence rate.

The team summarizes the study’s contributions as:
- Two RL formulations to train policies that provide coarse (scalar) and fine (vector) grain updates to the internal parameters of a QP solver for faster convergence times.
- Policies trained jointly across QP problem classes or to specialize to specific classes.
- Experimental results showing that RLQP reduces convergence times by up to 3x and generalizes to different problem classes and outperforms existing methods.

The team performed their speed-up on the OSQP solver, which solves QPs using a first-order alternating direction method of multipliers (ADMM), an efficient first-order optimization algorithm. The RLQP strives to learn a policy to adapt the internal parameters of the ADMM algorithm between iterations in order to minimize solve times. As the dimensions of this internal parameter vary between QPs, the team proposes two methods to handle the variation in dimensions: 1) Learning a policy to adapt a scalar of the internal parameter; 2) Learning a policy to adapt individual coefficients of the internal parameter.

The researchers use Twin-Delayed DDPG TD3, an extension of deep deterministic policy gradients (DDPG), to compute the policy (Algorithm 1 in the paper). They note that for some QP classes, the solver can further speed up convergence by adapting all coefficients of the internal parameter instead of adapting to scalar, i.e. using a vector (Algorithm 2 in the paper).
To train and test their proposed method, the team trained a network using randomly generated QPs from OSQP’s benchmark suite. They evaluated all policies (including control, Huber fitting, support-vector machines (SVM), Lasso regression, Portfolio optimization, equality constrained, and random QP domains) on a broad class of problems.
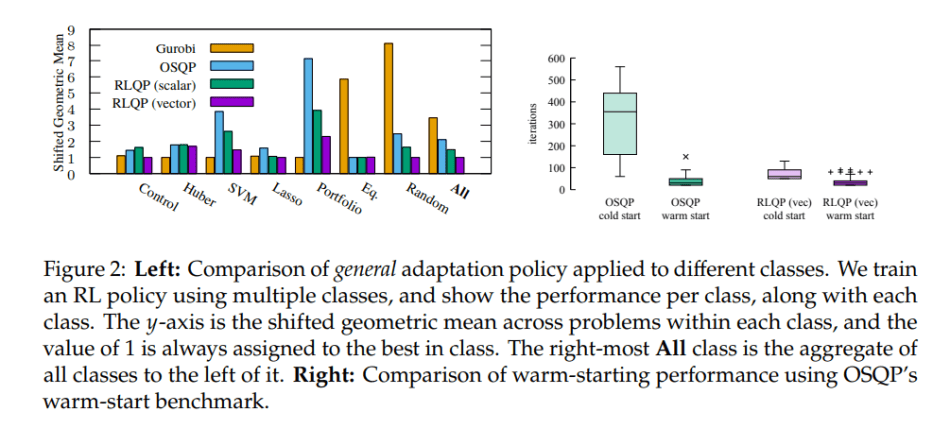

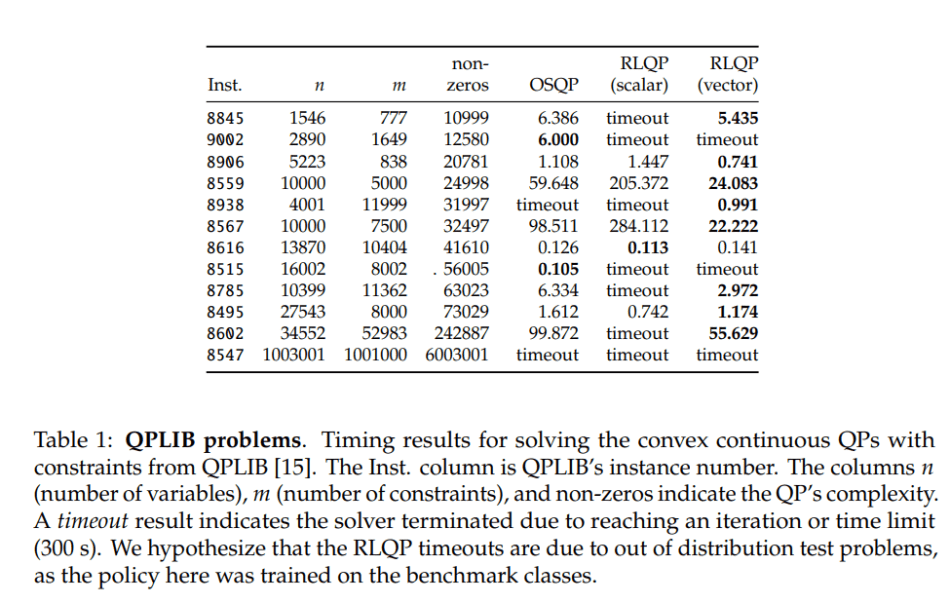
The results suggest that RLQP reduces convergence times by up to three times, generalizes well across problem classes, and outperforms existing methods. The team says that in future work, they will explore additional RL policy options to further speed-up convergence rate, such as training a hierarchical policy, using meta-learning, and online learning.
The paper Accelerating Quadratic Optimization with Reinforcement Learning is on arXiv.
Author: Hecate He | Editor: Michael Sarazen, Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: r/artificial - [R] Accelerating Quadratic Optimization Up to 3x With Reinforcement Learning - Cyber Bharat
good article thanks