
This is the age of deep neural networks (DNNs), which have proven effective across a wide range of AI applications. While large-scale DNN models learn faster and outperform their slimmer counterparts, these heavy models’ voracious resource appetites have limited their real-world deployment.
Pruning is one of the most popular DNN compression methods, aiming to reduce redundant structures to achieve slimmer architectures and also improve the interpretability of DNN models. Existing pruning methods however are usually heuristic, task-specific, time-consuming, and lack generalization ability.
In the paper Only Train Once: A One-Shot Neural Network Training And Pruning Framework, a research team from Microsoft, Zhejiang University, Johns Hopkins University, Georgia Institute of Technology and University of Denver addresses this issue with a one-shot DNN pruning framework that enables developers to obtain a slim architecture from a full heavy model without fine-tuning. The novel approach achieves significant FLOPs reductions while maintaining high performance.

The team summarizes their main contributions as:
- One-Shot Training and Pruning. Propose OTO, a one-shot training and pruning framework that compresses a full neural network into a slimmer one with competitive performance by Only-Train-Once. OTO dramatically simplifies the complex multi-stage training pipelines of the existing pruning approaches, fits various architectures and applications, and hence is generic and efficient.
- Zero-Invariant Group. Define zero-invariant groups for neural networks. If a network is partitioned into ZIGs, it allows us to prune the zero groups without affecting the output, which results in one-shot pruning. Such property is applicable to various popular structures from plain fully connected layers to sophisticated ones such as residual blocks and multi-head attention.
- Novel Structured-Sparsity Optimization Algorithm. Propose Half-Space Stochastic Projected Gradient (HSPG), a method that solves structured-sparsity inducing regularization problem. The team shows and analyzes the superiority of HSPG in promoting zero groups of networks than the standard proximal methods and the competitive objective convergence in practice. The fact that ZIG and HSPG are designed agnostic to networks makes OTO generic to various applications.
- Experimental Results. Train and compress full models simultaneously from scratch without fine-tuning for inference speedup and parameter reduction, and achieve state-of-the-art results on compression benchmark VGG for CIFAR10, ResNet50 for CIFAR10/ImageNet, Bert for SQuAD.

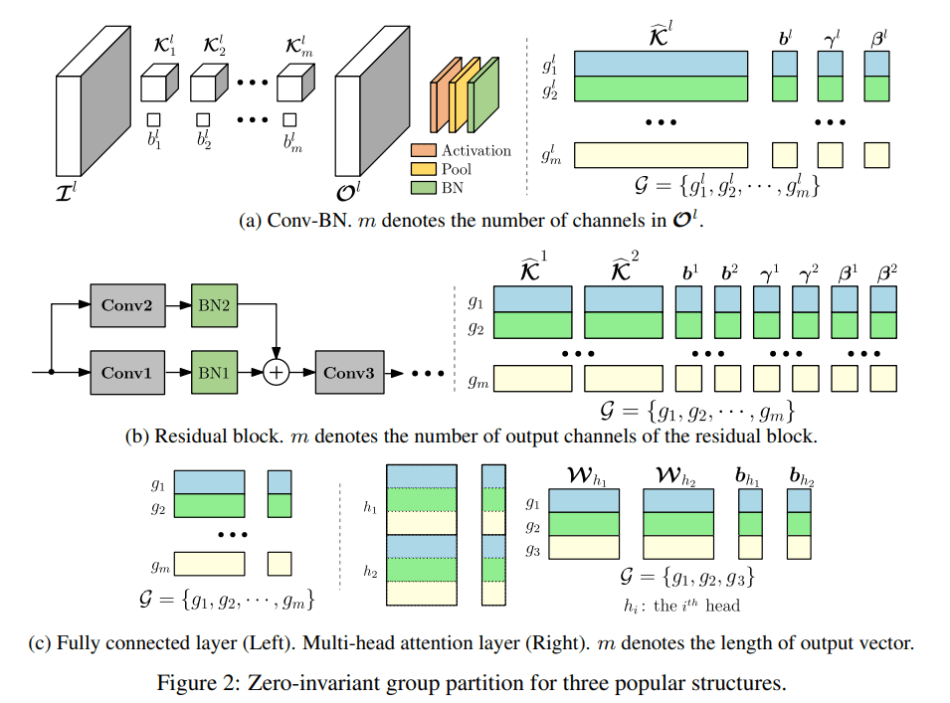
The OTO structure is relatively simple. Given a full model, the trainable parameters are first partitioned into a zero-invariant groups (ZIG) set. A structured-sparsity-inducing optimization problem is then constructed and solved via a novel stochastic optimizer (HSPG) to find a highly group-sparse solution. Finally, by directly pruning these zero groups, a compressed model can be obtained.

The team’s proposed HSPG stochastic optimization algorithm is designed to solve the non-smooth regularization problem, and can enhance group sparsity exploration more effectively than classical methods while maintaining similar convergence properties.
To evaluate OTO performance in one-shot training and pruning without fine-tuning, the team conducted empirical studies on benchmark compression tasks for CNNs: VGG16 for CIFAR10; ResNet50 for CIFAR10 and ImagetNet (ILSVRC2012). They compared OTO to its state-of-the-art counterparts in Top-1/5 accuracy, remaining FLOPs and parameters against the corresponding baseline.



In VGG16 for CIFAR10 experiments, OTO achieved an impressive 83.7 percent FLOPs reduction and 97.5 percent parameter reduction with the best Top-1 accuracy. In the ResNet50 for CIFAR10 experiments, OTO outperformed state-of-the-art automatic neural network compression frameworks AMC and ANNC without quantization, using only 12.8 percent of the FLOPs and 8.8 percent of the parameters. In the ResNet50 for ImageNet experiments, OTO pruned 64.5 percent of the parameters to achieve a 65.5 percent FLOPs reduction with only 1.4 percent/0.8 percent Top1/5 accuracy regression compared to the baseline.
Overall, the proposed OTO achieved state-of-the-art pruning results on all compression benchmark experiments, demonstrating the model’s strong potential. The team says future research could include incorporating quantization and applying OTO to various other tasks.
The paper Only Train Once: A One-Shot Neural Network Training And Pruning Framework is on arXiv.
Author: Hecate He | Editor: Michael Sarazen, Chain Zhang

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: r/artificial - [R] Only Train Once: SOTA One-Shot DNN Training and Pruning Framework - Cyber Bharat