
One of the continuing challenges in the AI research community is the development of systems that can learn useful representations without the need for any human annotations. While approaches to unsupervised representation learning from images have been largely based on data augmentation techniques, videos can provide their own natural augmentations of visual content under changing factors such as motion, deformation, occlusion and illumination. As such, unsupervised learning in videos is increasingly researched using additional modalities such as optical-flow, audio, and text to transfer supervision from one modality to another.
A research team from Facebook AI recently published a large-scale study on unsupervised spatiotemporal representation learning from videos, aiming to compare the various meta-methodologies on common ground. With a unified perspective on four current image-based frameworks (MoCo, SimCLR, BYOL, SwAV), the team identifies a simple objective they say can easily generalize all these methodologies to space-time.

The researchers identify five key components of their study:
- Four unsupervised learning frameworks (MoCo, SimCLR, BYOL, SwAV) viewed from a unified perspective and incorporated with a simple temporal persistency objective.
- Three pretraining datasets, including the relatively well-controlled Kinetics and the relatively “in-the-wild” Instagram sets at million-scale.
- Six downstream datasets/tasks for evaluating representation quality.
- Ablation experiments on different factors, such as temporal samples, contrastive objective, momentum encoders, training duration, backbones, data augmentation, curated vs. uncurated, trimmed vs. untrimmed, etc.
- State-of-the-art results of unsupervised video representation learning on established benchmarks, UCF-101, HMDB51 and Kinetics-400.

The four involved image-based frameworks for learning image representations share the same objective: learning invariant features across different views (crops/augmentations) of a spatial image input. The idea behind the work is to extend this spatial approach to the temporal domain and train a spatiotemporal encoder that generates embeddings that are persistent in space-time over multiple temporally distant clips of the same video.
Specifically, the SimCLR framework uses embeddings of clips from other videos in its minibatch as negatives, while MoCo uses an explicit momentum encoder to compute the positive embeddings from clips of the same video and negative embeddings obtained from a queue that stores embeddings of clips from previous iterations. BYOL is similar to MoCo but does not use negative samples and adds an extra Multi-Layer Predictor, and SwAV is similar to SimCLR but does not use negative samples.
The team implemented these methods with a symmetric loss, where every input clip is used to produce a loss. For MoCo and BYOL, the symmetric loss is aggregated sequentially, while for SimCLR and SwAV the overall loss is evaluated in parallel across all clips.
The researchers performed unsupervised pretraining on Kinetics-400 (K400) with ∼240k training videos in 400 human action categories and measured top-1 classification accuracy (%) on the K400 validation set and finetuning accuracy on the UCF101, AVA, Charades, Something-Something and HMDB51 datasets. They selected a ResNet-50 convolutional neural network as their default architecture.
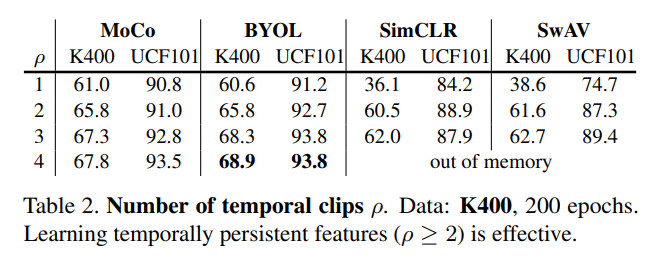
Results on the temporal augmentation experiments showed that accuracy increases as the number of temporal samples per video increases. For instance, the best accuracy was achieved with BYOL at 68.9 percent K400 and 93.8 percent UCF101 when the number of temporal samples reached four (the maximal number in the experiments). The researchers report two important findings: learning space-time persistence within a video is key for the methods, but learning in-persistence across videos is not; and there is a clear difference between methods that employ momentum encoders (MoCo, BYOL) and those that do not (SimCLR, SwAV).
The team conducted additional experiments such as data augmentation testing, colour augmentation testing and backbone architectures comparison; and compared the performance of all four methodologies on uncurated data. The results demonstrated that it is beneficial to sample positives with longer timespan intervals, contrastive objectives are less influential than momentum encoders, and that training duration, backbones, video augmentation and curation are all critical for good performance.
The paper A Large-Scale Study on Unsupervised Spatiotemporal Representation Learning is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: [R] Facebook AI Conducts Large-Scale Study on Unsupervised Spatiotemporal Representation Learning : MachineLearning - TechFlx
Pingback: [R] Facebook AI Conducts Large-Scale Study on Unsupervised Spatiotemporal Representation Learning – ONEO AI
Pingback: r/artificial - [R] Facebook AI Conducts Large-Scale Study on Unsupervised Spatiotemporal Representation Learning - Cyber Bharat