
The basic idea behind imitation learning is implicitly giving a robotic entity prior information about the world by mimicking human behaviour. Through such techniques, which can be likened to behaviour cloning or inverse reinforcement learning, it is possible to increase the efficiency of robots and their interaction capacities with humans, while also decreasing the cost involved in learning new skills.
Inspired by the idea that a robotic manipulator can imitate any visually-demonstrated behaviour of arbitrary complexity, a DeepMind research team has proposed manipulation-independent representations (MIR) that can support successful imitation of behaviours demonstrated by previously unseen manipulator morphologies using only visual observations.

The researchers first explain how to imitate unconstrained manipulation trajectories executed by previously unknown manipulators, specifically how to learn pixel-based representations that produce the right information for a cross-embodiment trajectory tracking agent. The proposed imitation method has two main phases: learning an MIR space, and cross-embodiment visual imitation through reinforcement learning using the pretrained MIR space.
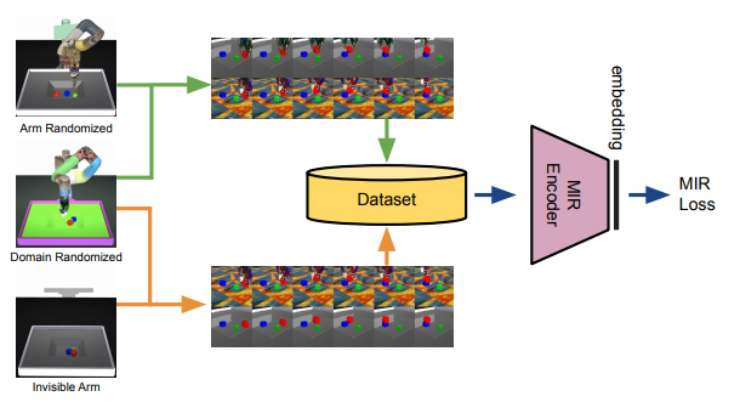

The team identified three main properties of the desired MIR space that support imitation from unseen manipulator trajectories: cross-domain alignment, temporal smoothness, and being actionable (suitability for reinforcement learning).
For cross-domain alignment, the researchers trained a common embedding space designed to close the large domain gaps amongst trajectories. To secure temporal smoothness (an important property for robots to reach goals specified through visual observations), the team proposed Temporally-Smooth Contrastive Networks (TSCN), with a loss function that urges the learned representation to be more temporally smooth and includes negative pairs that further improve the alignment quality. To make the representations actionable, they utilized several levels of domain randomization in their simulated environments, which helped the representation focus on the actual change in the environment and capture the rough position and properties of a manipulator.
To determine whether the proposed MIR had the above properties and evaluate its performance on unconstrained manipulation trajectories imitation through unknown manipulators, the team conducted experiments on eight environments and scenarios: Canonical Simulation, Invisible Arm, Arm Randomized, Domain Randomized, Jaco Hand, Real Robot, Pick-up Stick and Human Hand. They also compared MIR with baseline methods, including naive Goal Conditioned Policies (GCP), Temporal Distance Classification (TDC), Time-Contrastive Networks (TCN) and Cross-Modal Distance Classification (CMC).


In the evaluations, MIR achieved the best performance across all test domains, significantly boosting Jaco Hand performance on stacking success and perfectly imitating the simulated Jaco Hand and Invisible Arm on lifting, with a 100 percent score.
Overall, the study revealed the important considerations in learning manipulator and task-independent representations for imitation, and validated the proposed MIR’s characteristics for successful cross embodiment visual imitation.
The paper Manipulator-Independent Representations for Visual Imitation is on arXiv.
Author: Hecate He | Editor: Michael Sarazen

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: [N] DeepMind Proposes Manipulation-Independent Representations for Imitation of Behaviours Demonstrated by Previously Unseen Manipulator Morphologies – ONEO AI
Pingback: r/artificial – [N] DeepMind Proposes Manipulation-Independent Representations for Imitation of Behaviours Demonstrated by Previously Unseen Manipulator Morphologies | Cyber Bharat
Google Always have a great mission for their users.Google Says “Our mission is to organize the world’s information and make it universally accessible and useful.”
I have part 1 of Hitchhiker’s. Should I read it or find the other parts before I begin? I loved Da Vinci Code when I read it eons ago.