Researchers from UC Berkeley and Google Research have introduced BoTNet, a “conceptually simple yet powerful” backbone architecture that boosts performance on computer vision (CV) tasks such as image classification, object detection and instance segmentation.
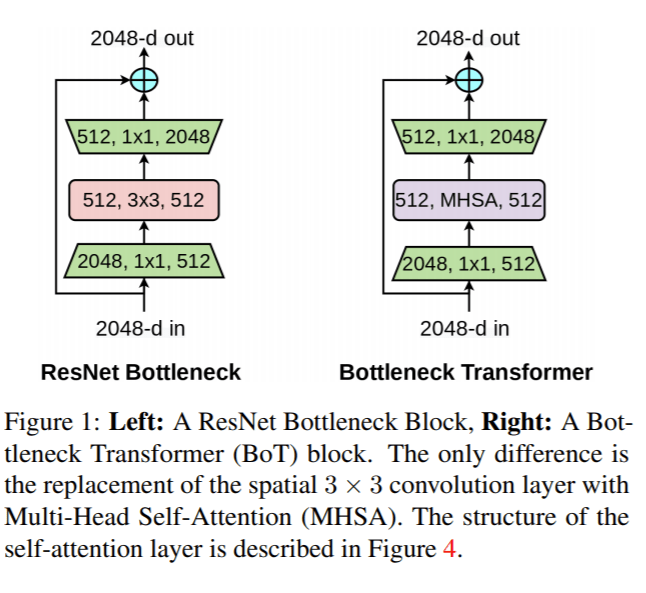
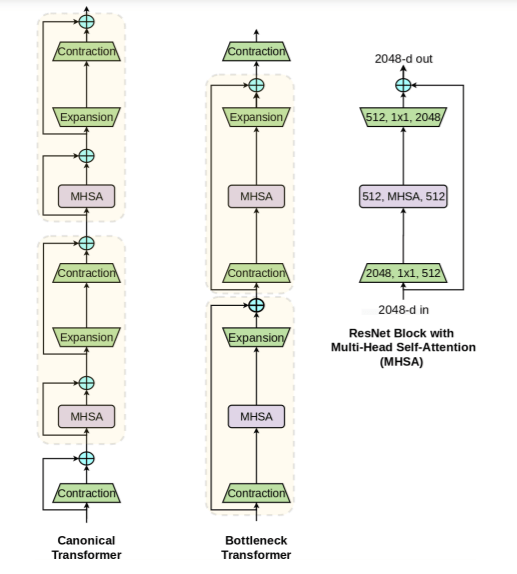
In the paper Bottleneck Transformers for Visual Recognition, researchers describe BoTNet as a deep learning architecture that enables hybrid models to use both convolutions and self-attention. The design’s key innovation is replacing the spatial 3 × 3 convolution layer in the final three bottleneck blocks of a residual neural network (ResNet) with Multi-Head Self-Attention (MHSA). The team says that the simple design change enables the ResNet bottleneck blocks to be viewed as Transformer blocks.

Although stacking more layers in a convolution-based architecture can improve the modelling of long-range dependencies — as required for many CV tasks — the researchers propose a simpler solution that leverages self-attention. They explain that since the self-attention mechanism can learn a rich hierarchy of associative features across long sequences, this computation primitive can also benefit CV tasks. Take the task of instance segmentation as an example. Modelling long-range dependencies such as collecting and associating scene information from a large neighbourhood can help to learn relationships across objects.
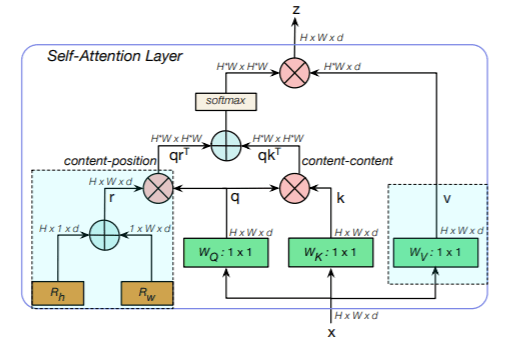
“A simple approach to using self-attention in vision is to replace spatial convolutional layers with the multi-head self-attention (MHSA) layer proposed in the Transformer,” the researchers explain. Unlike previous deep learning architectures using self-attention for visual recognition that employ self-attention outside the backbone architecture, BoTNet uses both convolutions and self-attention within its backbone architecture to implement global self-attention over a 2D feature map.
Most CV landmark backbone architectures have multiple layers of 3×3 convolutions, and ResNet’s leaner bottleneck architectures have been widely used to reduce computational cost. Through extensive experiments, the team concluded that BoTNet is applicable as a drop-in replacement for any ResNet backbone, and that with a more efficient compute steptime, replacing convolutions is more efficient than stacking convolutions.

Notoriously, the memory and compute required for self-attention scales quadratically with spatial dimensions, often leading to prohibitive overheads for training and inference. That’s why the researchers chose the hybrid design, where convolutions are responsible for first efficiently learning abstract and low-resolution feature maps from large images. The global self-attention mechanism then processes and aggregates the information provided by the feature maps captured by the convolutions.
Evaluated On the COCO Instance Segmentation benchmark validation set, BoTNet’s 44.4 percent Mask AP and 49.7 percent Box AP performance surpassed the previous best single model and single scale results of ResNeSt. Moreover, the BoTNet design enabled models to achieve a robust result on the ImageNet benchmark for image classification, with an 84.7 percent top-1 accuracy. In terms of compute time, the proposed method is 2.33x faster than popular EfficientNet models on TPU-v3 hardware.
The researchers hope their simple yet effective approach can serve as a strong baseline for future research on leveraging self-attention models for CV tasks.
The paper Bottleneck Transformers for Visual Recognition is on arXiv.
Journalist: Fangyu Cai | Editor: Michael Sarazen

Synced Report | A Survey of China’s Artificial Intelligence Solutions in Response to the COVID-19 Pandemic — 87 Case Studies from 700+ AI Vendors
This report offers a look at how China has leveraged artificial intelligence technologies in the battle against COVID-19. It is also available on Amazon Kindle. Along with this report, we also introduced a database covering additional 1428 artificial intelligence solutions from 12 pandemic scenarios.
Click here to find more reports from us.

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: [N] UC Berkeley & Google’s BoTNet Applies Self-Attention to CV Bottlenecks – ONEO AI
very good
So, I was collecting funds for a new smartwatch. A sequence of unlucky spins had drained my entertainment budget. Almost ready to quit, I risked a larger amount on a single hand of blackjack and was dealt a natural blackjack. The watch is now a daily companion. That hand was played at spinsala . The mobile experience is flawless, making it easy to play during commutes. Their weekly reload bonuses offer consistent value. It has become my preferred destination for casual play.