
A new study by the Georgia Institute of Technology and Facebook AI introduces TT-Rec (Tensor-Train for DLRM), a method designed to drastically compress the size of memory-intensive Deep Learning Recommendation Models (DLRM) and make them easier to deploy at scale. The proposed method’s key innovation is the replacement of DLRMs’ large embedding tables with a sequence of matrix products using tensor train decomposition.
Neural network-based personalization and recommendation models have become essential tools for content platforms like Netflix and YouTube and tech giants like Facebook that build recommendation systems in production environments. There are two main components in such constructed DLRMs: MultiLayer Perceptron (MLP) layer modules and Embedding Tables (EMBs). While the MLP layers deal with continuous features such as user age, the EMBs are responsible for processing categorical features by encoding sparse, high-dimensional inputs into dense vector representations.

The paper TT-Rec: Tensor Train Compression for Deep Learning Recommendation Models notes that the memory capacity of embedding tables in industry DLRMs is increasing from gigabytes to terabytes. The resource-hungry DLRMs in Facebook’s data centers, for example, eat up more than 50 percent of training time and 80 percent of AI inference cycles, with their large embedding tables comprising 99 percent of the total recommendation model capacity. There can be tens of millions of rows in an embedding table, and this number is growing exponentially across new recommendation models, pushing memory requirements well into the TB scale.
With the increasing adaptation of increasingly large DLRMs, there is an urgent need to develop fast and efficient DLRMs that won’t lead to exponential increases in infrastructure capacity demands.
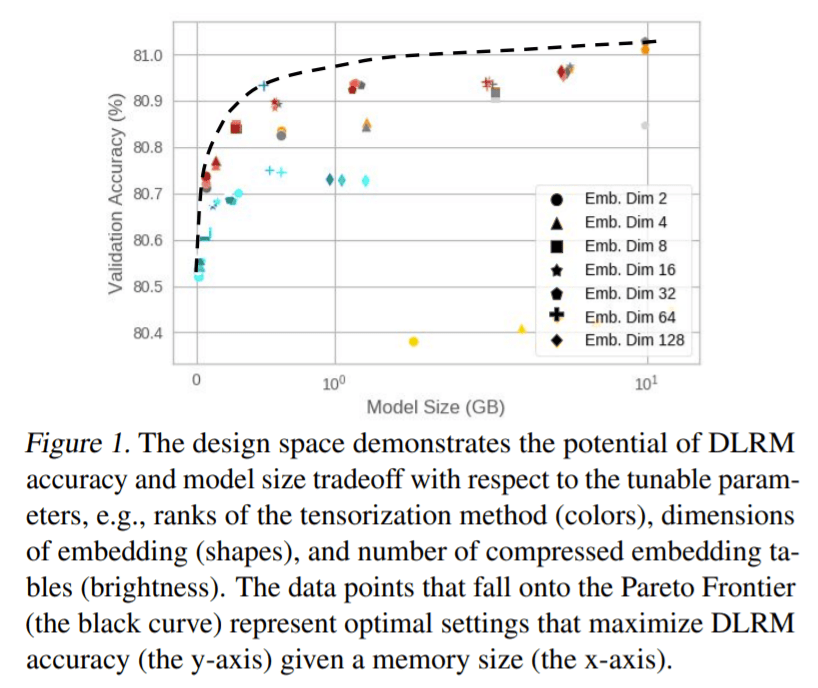

To achieve such a goal, the researchers designed TT-Rec’s compression technique to replace large embedding tables in a DLRM with a sequence of matrix products. Tensor-train decomposition can produce matrix decomposition by decomposing tensor representations of multidimensional data into smaller tensors. The researchers liken their proposed method to techniques that use lookup tables to trade-off memory storage and bandwidth with computation. As a result, the embedding vectors are replaced with 3-dimension tensors (TT-core multiplication). The researchers also introduced a cache structure in TT-Rec to exploit the unique sparse feature distribution in DLRMs, which empirically improves accuracy.
To evaluate their approach, the team trained MLPerf-DLRM with Criteo’s Kaggle and Terabyte datasets. In experiments the proposed TT-Rec reduced total model memory capacity requirement by up to 112 times with only a 13.9 percent increase in training time while maintaining model accuracy against the baseline.

The researchers believe TT-Rec’s memory capacity reductions are significant given the relatively small increase in training time, and that the technique can make online recommendation model training more efficient and practical.
The paper TT-Rec: Tensor Train Compression for Deep Learning Recommendation Models is on arXiv, and the code is available on the project GitHub.
Journalist: Fangyu Cai | Editor: Michael Sarazen
Pingback: [N] Georgia Tech & Facebook Tensor Train Approach Achieves 112x Size Reduction in DL Recommendation Models – ONEO AI
Thanks for taking your time to write this
You have brought up a very superb points , thanks for the post.