Transformers are a class of attention-based neural architectures that have enabled advanced pretrained language models such as Google’s BERT and OpenAI’s GPT series and produced numerous breakthroughs in speech recognition and other natural language processing (NLP) tasks since their debut in 2017. Transformers perform exceptionally well on problems with sequential data, and have more recently been extended to reinforcement learning, computer vision and symbolic mathematics.
This year, 22 Transformer-related research papers were accepted by NeurIPS, the world’s most prestigious machine learning conference. Synced has selected ten of these works to showcase the latest Transformer trends — from extended use of the neural architecture to innovative advancements in technique, architectural design changes and more.
Extended Use of Transformers
- SE(3)-Transformers: 3D Roto-Translation Equivariant Attention Networks
- Fabian Fuchs, Daniel Worrall, Volker Fischer, Max Welling
SE(3)-Transformers are a new variant of the self-attention module proposed by researchers from Bosch Center for Artificial Intelligence and the University of Amsterdam.
Abstract: We introduce the SE(3)-Transformer, a variant of the self-attention module for 3D point-clouds, which is equivariant under continuous 3D roto-translations. Equivariance is important to ensure stable and predictable performance in the presence of nuisance transformations of the data input. A positive corollary of equivariance is increased weight-tying within the model. The SE(3)-Transformer leverages the benefits of self-attention to operate on large point clouds with varying number of points, while guaranteeing SE(3)-equivariance for robustness. We evaluate our model on a toy N-body particle simulation dataset, showcasing the robustness of the predictions under rotations of the input. We further achieve competitive performance on two real-world datasets, ScanObjectNN and QM9. In all cases, our model outperforms a strong, non-equivariant attention baseline and an equivariant model without attention
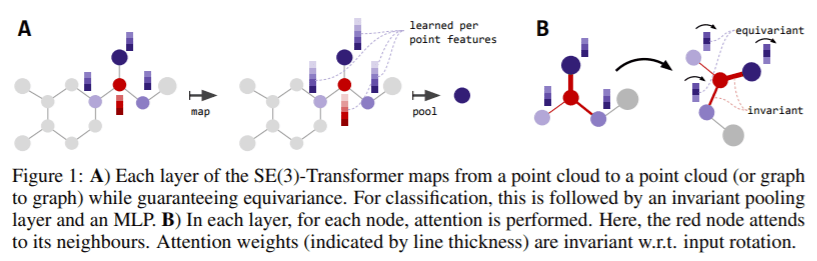
- Self-Supervised Graph Transformer on Large-Scale Molecular Data
- Yu Rong, Yatao Bian, Tingyang Xu, Weiyang Xie, Ying WEI, Wenbing Huang, Junzhou Huang
A work from Tencent AI Lab, Beijing National Research Center for Information Science and Technology and Tsinghua University proposes the novel framework, Graph Representation frOm self-superVised mEssage passing tRansformer, GROVER.
Abstract: How to obtain informative representations of molecules is a crucial prerequisite in AI-driven drug design and discovery. Recent researches abstract molecules as graphs and employ Graph Neural Networks (GNNs) for molecular representation learning. Nevertheless, two issues impede the usage of GNNs in real scenarios: (1) insufficient labeled molecules for supervised training; (2) poor generalization capability to new-synthesized molecules. To address them both, we propose a novel framework, GROVER, which stands for Graph Representation frOm self-superVised mEssage passing tRansformer. With carefully designed self-supervised tasks in node-, edge- and graph-level, GROVER can learn rich structural and semantic information of molecules from enormous unlabelled molecular data. Rather, to encode such complex information, GROVER integrates Message Passing Networks into the Transformer-style architecture to deliver a class of more expressive encoders of molecules. The flexibility of GROVER allows it to be trained efficiently on large-scale molecular dataset without requiring any supervision, thus being immunized to the two issues mentioned above. We pre-train GROVER with 100 million parameters on 10 million unlabelled molecules—the biggest GNN and the largest training dataset in molecular representation learning. We then leverage the pre-trained GROVER for molecular property prediction followed by task-specific fine-tuning, where we observe a huge improvement (more than 6% on average) from current state-of-the-art methods on 11 challenging benchmarks. The insights we gained are that well-designed self-supervision losses and largely-expressive pre-trained models enjoy the significant potential on performance boosting.

- RelationNet++: Bridging Visual Representations for Object Detection via Transformer Decoder
- Cheng Chi, Fangyun Wei, Han Hu
Researchers from the Chinese Academy of Sciences and Microsoft Research Asia bridge various visual representations with a Transformer-like attention mechanism designed to enhance the main representation in a object detector.
Abstract: Existing object detection frameworks are usually built on a single format of object/part representation, i.e., anchor/proposal rectangle boxes in RetinaNet and Faster R-CNN, center points in FCOS and RepPoints, and corner points in CornerNet. While these different representations usually drive the frameworks to perform well in different aspects, e.g., better classification or finer localization, it is in general difficult to combine these representations in a single framework to make good use of each strength, due to the heterogeneous or non-grid feature extraction by different representations. This paper presents an attention-based decoder module similar as that in Transformer to bridge other representations into a typical object detector built on a single representation format, in an end-to-end fashion. The other representations act as a set of key instances to strengthen the main query representation features in the vanilla detectors. Novel techniques are proposed towards efficient computation of the decoder module, including a key sampling approach and a shared location embedding approach. The proposed module is named bridging visual representations (BVR). It can perform in-place and we demonstrate its broad effectiveness in bridging other representations into prevalent object detection frameworks, including RetinaNet, Faster R-CNN, FCOS and ATSS, where about 1.5 ∼ 3.0 AP improvements are achieved. In particular, we improve a state-of-the-art framework with a strong backbone by about 2.0 AP, reaching 52.7 AP on COCO test-dev. The resulting network is named RelationNet++. The code is available at https://github.com/microsoft/RelationNet2.

- Neurosymbolic Transformers for Multi-Agent Communication
- Jeevana Priya Inala, Yichen Yang, James Paulos, Yewen Pu, Osbert Bastani, Vijay Kumar, Martin Rinard, Armando Solar-Lezama
MIT CSAIL and University of Pennsylvania researchers combine Transformers and programmatic communication policies in a neurosymbolic Transformer to reduce the amount of communication in cooperative multi-agent planning problems.
Abstract: We study the problem of inferring communication structures that can solve cooperative multi-agent planning problems while minimizing the amount of communication. We quantify the amount of communication as the maximum degree of the communication graph; this metric captures settings where agents have limited bandwidth. Minimizing communication is challenging due to the combinatorial nature of both the decision space and the objective; for instance, we cannot solve this problem by training neural networks using gradient descent. We propose a novel algorithm that synthesizes a control policy that combines a programmatic communication policy used to generate the communication graph with a transformer policy network used to choose actions. Our algorithm first trains the transformer policy, which implicitly generates a “soft” communication graph; then, it synthesizes a programmatic communication policy that “hardens” this graph, forming a neurosymbolic transformer. Our experiments demonstrate how our approach can synthesize policies that generate low-degree communication graphs while maintaining near-optimal performance.

Innovative Technique Advancements
- Deep Transformers with Latent Depth
- Xian Li, Asa Cooper Stickland, Yuqing Tang, Xiang Kong
This work by FacebookAI proposesa novel method for training deep Transformers to learn the effective network depth.
Abstract: The Transformer model has achieved state-of-the-art performance in many sequence modeling tasks. However, how to leverage model capacity with large or variable depths is still an open challenge. We present a probabilistic framework to automatically learn which layer(s) to use by learning the posterior distributions of layer selection. As an extension of this framework, we propose a novel method to train one shared Transformer network for multilingual machine translation with different layer selection posteriors for each language pair. The proposed method alleviates the vanishing gradient issue and enables stable training of deep Transformers (e.g. 100 layers). We evaluate on WMT English-German machine translation and masked language modeling tasks, where our method outperforms existing approaches for training deeper Transformers. Experiments on multilingual machine translation demonstrate that this approach can effectively leverage increased model capacity and bring universal improvement for both many-to-one and one-to-many translation with diverse language pairs.

- Accelerating Training of Transformer-Based Language Models with Progressive Layer Dropping
- Minjia Zhang, Yuxiong He
Microsoft researchers propose a method based on progressive layer dropping to accelerate the training of Transformer-based language models.
Abstract: Recently, Transformer-based language models have demonstrated remarkable performance across many NLP domains. However, the unsupervised pre-training step of these models suffers from unbearable overall computational expenses. Current methods for accelerating the pre-training either rely on massive parallelism with advanced hardware or are not applicable to language models. In this work, we propose a method based on progressive layer dropping that speeds the training of Transformer-based language models, not at the cost of excessive hardware resources but from model architecture change and training technique boosted efficiency. Extensive experiments on BERT show that the proposed method achieves a 25% reduction of computation cost in FLOPS and a 24% reduction in the end-to-end wall-clock training time. Furthermore, we show that our pre-trained models are equipped with strong knowledge transferability, achieving similar or even higher accuracy in downstream tasks to baseline models.
- Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing
- Zihang Dai, Guokun Lai, Yiming Yang, Quoc Le
CMU and Google AI researchers’ proposed Funnel-Transformer filters out sequential redundancy to lower compute cost.
Abstract: With the success of language pretraining, it is highly desirable to develop more efficient architectures of good scalability that can exploit the abundant unlabeled data at a lower cost. To improve the efficiency, we examine the much-overlooked redundancy in maintaining a full-length token-level presentation, especially for tasks that only require a single-vector presentation of the sequence. With this intuition, we propose Funnel-Transformer which gradually compresses the sequence of hidden states to a shorter one and hence reduces the computation cost. More importantly, by re-investing the saved FLOPs from length reduction in constructing a deeper or wider model, we further improve the model capacity. In addition, to perform token-level predictions as required by common pretraining objectives, Funnel-Transformer is able to recover a deep representation for each token from the reduced hidden sequence via a decoder. Empirically, with comparable or fewer FLOPs, Funnel-Transformer outperforms the standard Transformer on a wide variety of sequence-level prediction tasks, including text classification, language understanding, and reading comprehension.

Change of Design on the Architectural Mechanism
- Big Bird: Transformers for Longer Sequences
- Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed
As Synced previously reported, in this work Google researchers introduce a sparse attention mechanism dubbed BigBird to alleviate the quadratic dependency of Transformers.
Abstract: Transformers-based models, such as BERT, have been one of the most successful deep learning models for NLP. Unfortunately, one of their core limitations is the quadratic dependency (mainly in terms of memory) on the sequence length due to their full attention mechanism. To remedy this, we propose, BigBird, a sparse attention mechanism that reduces this quadratic dependency to linear. We show that BigBird is a universal approximator of sequence functions and is Turing complete, thereby preserving these properties of the quadratic, full attention model. Along the way, our theoretical analysis reveals some of the benefits of having O(1)O(1) global tokens (such as CLS), that attend to the entire sequence as part of the sparse attention mechanism. The proposed sparse attention can handle sequences of length up to 8x of what was previously possible using similar hardware. As a consequence of the capability to handle longer context, BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also propose novel applications to genomics data.

- O(n) Connections are Expressive Enough: Universal Approximability of Sparse Transformers
- Chulhee Yun, Yin-Wen Chang, Srinadh Bhojanapalli, Ankit Singh Rawat, Sashank Reddi, Sanjiv Kumar
A team from MIT and Google Research designs a unifying framework to provide a theoretical understanding of available sparse Transformer models.
Abstract: Recently, Transformer networks have redefined the state of the art in many NLP tasks. However, these models suffer from quadratic computational cost in the input sequence length nn to compute pairwise attention in each layer. This has prompted recent research into sparse Transformers that sparsify the connections in the attention layers. While empirically promising for long sequences, fundamental questions remain unanswered: Can sparse Transformers approximate any arbitrary sequence-to-sequence function, similar to their dense counterparts? How does the sparsity pattern and the sparsity level affect their performance? In this paper, we address these questions and provide a unifying framework that captures existing sparse attention models. We propose sufficient conditions under which we prove that a sparse attention model can universally approximate any sequence-to-sequence function. Surprisingly, our results show that sparse Transformers with only O(n) connections per attention layer can approximate the same function class as the dense model with n2 connections. Lastly, we present experiments comparing different patterns/levels of sparsity on standard NLP tasks.
- Fast Transformers with Clustered Attention
- Apoorv Vyas, Angelos Katharopoulos, François Fleuret
Idiap Research Institute, École Polytechnique Fédérale de Lausanne, and University of Geneva researchers put a spin on the self-attention mechanism.
Abstract:Transformers have been proven a successful model for a variety of tasks in sequence modeling. However, computing the attention matrix, which is their key component, has quadratic complexity with respect to the sequence length, thus making them prohibitively expensive for large sequences. To address this, we propose clustered attention, which instead of computing the attention for every query, groups queries into clusters and computes attention just for the centroids. To further improve this approximation, we use the computed clusters to identify the keys with the highest attention per query and compute the exact key/query dot products. This results in a model with linear complexity with respect to the sequence length for a fixed number of clusters. We evaluate our approach on two automatic speech recognition datasets and show that our model consistently outperforms vanilla transformers for a given computational budget. Finally, we demonstrate that our model can approximate arbitrarily complex attention distributions with a minimal number of clusters by approximating a pretrained BERT model on GLUE and SQuAD benchmarks with only 25 clusters and no loss in performance.
NeurIPS 2020 ran virtually December 6-12. The list of accepted papers is available on the conference website archive.
Reporter: Fangyu Cai | Editor: Michael Sarazen

Synced Report | A Survey of China’s Artificial Intelligence Solutions in Response to the COVID-19 Pandemic — 87 Case Studies from 700+ AI Vendors
This report offers a look at how China has leveraged artificial intelligence technologies in the battle against COVID-19. It is also available on Amazon Kindle. Along with this report, we also introduced a database covering additional 1428 artificial intelligence solutions from 12 pandemic scenarios.
Click here to find more reports from us.

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: [R] NeurIPS 2020 | Teaching Transformers New Tricks – tensor.io
Pingback: [R] NeurIPS 2020 | Teaching Transformers New Tricks – ONEO AI
I really like your blog.
Pingback: Heidelberg University Researchers Combine CNNs and Transformers to Synthesize High-Resolution Images | Synced
good article