
Let’s face it: the advanced AI systems of the future are unlikely to be built with data that’s been hand-labelled by humans. Finding ways to eliminate the time-consuming data-labelling process has been a challenge in the machine learning (ML) community for some time. A new paper from researchers at the University of Southern California and Amazon approaches the problem with a self-training framework that can improve information retrieval performance using unlabelled data.

Recent methods in self-supervised learning and self-training have shown promising results using unlabelled data. Existing methods for self-supervised learning or self-training however mainly focus on classification but not retrieval — the process of identifying and obtaining relevant information system resources such as texts, images, etc. The researchers’ proposed SeLf-trAining framework for Distance mEtric learning (SLADE) framework combines self-supervised learning and distance metric learning methods to improve information retrieval performance.
Distance metric learning is a research area where the basic objective is to push similar samples closer to each other and different samples away from each other. It can automatically construct task-specific distance metrics from (weakly) supervised data, and the learned distance metrics can then be used to perform various tasks.
The researchers first trained a teacher model on labelled data and used self-supervised representation learning to initialize the teacher model. Once the teacher model was pretrained and fine-tuned, they used it to generate pseudo labels for unlabelled data. They then trained a student model on both labels and pseudo labels to generate final feature embeddings.

To deal with the noisy pseudo labels generated by the teacher network, the researchers designed a new feature basis learning component for the student network. This comprises a new representation layer added after the embedding layer, which is only used for learning basis functions for the feature representation in unlabelled data.
The researchers say their learned basis vectors better measure the pairwise similarity for unlabelled data and can select high-confident samples for training the student network, which can then be used to extract embeddings of query images for retrieval.
The researchers evaluated SLADE on several standard retrieval benchmarks including CUB-200, Cars-196 and In-shop. The results show that the proposed approach can outperform SOTA methods on CUB-200 and Cars-196, is competitive on In-shop, and significantly boosts the performance of fully-supervised methods.
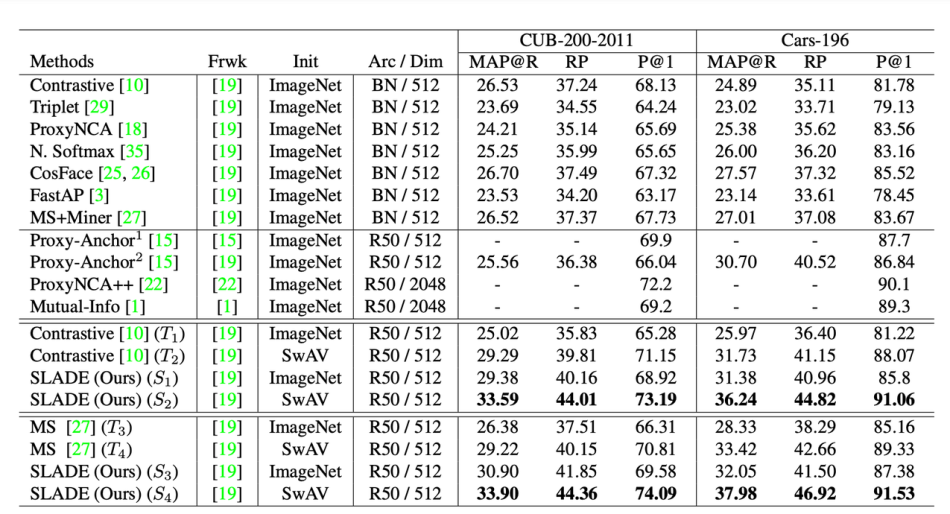
The paper SLADE: A Self-Training Framework For Distance Metric Learning is on arXiv.
Reporter: Yuan Yuan | Editor: Michael Sarazen

Synced Report | A Survey of China’s Artificial Intelligence Solutions in Response to the COVID-19 Pandemic — 87 Case Studies from 700+ AI Vendors
This report offers a look at how China has leveraged artificial intelligence technologies in the battle against COVID-19. It is also available on Amazon Kindle. Along with this report, we also introduced a database covering additional 1428 artificial intelligence solutions from 12 pandemic scenarios.
Click here to find more reports from us.

We know you don’t want to miss any news or research breakthroughs. Subscribe to our popular newsletter Synced Global AI Weekly to get weekly AI updates.
Pingback: [R] USC & Amazon ‘SLADE’ Self-Training Framework Uses Unlabelled Data to Improve Information Retrieval – tensor.io
Pingback: [R] USC & Amazon ‘SLADE’ Self-Training Framework Uses Unlabelled Data to Improve Information Retrieval > Seekalgo
Pingback: Data Science newsletter – November 30, 2020 | Sports.BradStenger.com